 Seeing is believing.
Seeing is believing.
Observing just a handful of users interact with a product can be more influential than reading pages of a professionally done report or polished presentation.
But what if a stakeholder only has time to watch two or just one of the users in a usability study?
Are there circumstances where watching some users is worse than watching no users at all?
Watching One is Worse than None
The idea is that if a stakeholder, like a product developer or executive, happens to see one out of the five users that didn’t struggle with a product, they would incorrectly think all five users didn’t have a problem and the study went much better than it actual did.
Two Users as Pattern
To offset this potential for overgeneralizing the results of a single user, some research teams have a plurality rule–they ask, or in some cases require, that stakeholders watch more than one session. If they can only watch one, then it’s worse than watching none.
If the result of all the effort that goes into planning and conducting a usability test is consistent misinterpretation, then it’s understandable why you’d have such a rule. At least with two users you’d be able to see how different users interact with the software and be more circumspect in drawing conclusions about what users do.
Three Users as Tie Breaker
Another variant on this I’ve seen is that the minimum number to observe should be three, not two users. With two users one session could go well and the other could bomb. In essence these cancel each other out and leaves the stakeholder wondering what conclusion to draw about the experience. With three there’s at least a tie-breaker.
Why One is Better Than None
I sympathize with researchers who have to manage stakeholders that will distort data to match their preconceived notions. So it’s understandable to have such guidelines. However, I wouldn’t go as far to say that one or two users is worse than watching none. And it comes down to some rules of probability.
Consider the table below, which represents five users from a usability study. The white squares are users who had similar experiences. The red square represents a user who had an unusual experience with the product (unusually bad or good).
The chance a stakeholder will see this one unusual session is 1 out of 5 or 20%. So in any study with just one unusual user, there’s a reasonable chance of being misled.
However, the law of large numbers tells us that over time, it’s much more likely a stakeholder will see a typical than atypical experience. Below are five more studies, each with five sessions. In each study there is one red square indicating an odd-ball experience and four consistent experiences (white squares).
Using the binomial probability formula, the probability a stakeholder will see only the unusual experience in all five sessions is .03%. The probability that the single session stakeholder will see at least three unusual experiences is 6%. Over time, the stakeholder who jumps in and out of just one session per study is much more likely to see a typical than atypical experience.
Problem Occurrence
We can also extend this to the problems users encounter. The same rules of probability that allow 5 users to reveal most of the obvious issues also means that the issues observed with just a single user are much more likely to be obvious issues than unusual ones. That is, if you see 1 out of 5 users have a problem, it is much more likely (8.5 times) that the problem affects 20% of users than 1% of users.
Unique Issues
When it comes to problem occurrences however, any given user will encounter multiple problems and depending on the type of study, many of these problems will only be seen once—even after testing many users. For example, the grid below shows a problem matrix from a usability test with 30 users. A total of 28 problems were recorded. Of these, 9 (32%) were encountered by just one user.
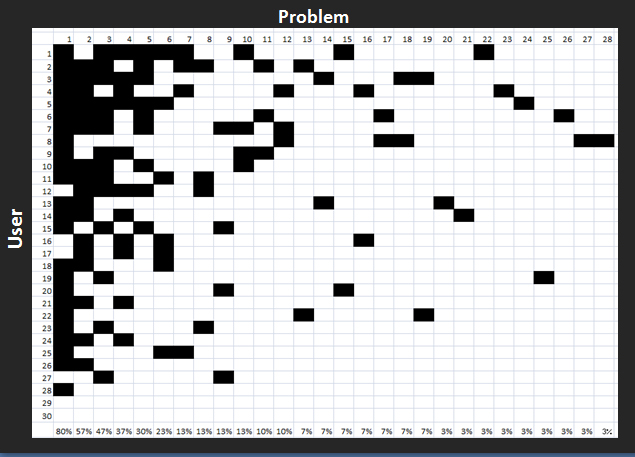
A clear drawback of observing just one user is that the stakeholder can’t distinguish between these unique issues and the more common ones. With just one user, all problems affect all users. With two or three users at least we have some ability to distinguish between unique and redundant problems. But we can’t overestimate the certainty we get by going from one to two or even thee users.
Small Sample Uncertainty
While the idea of three as a tie-breaker has a good appeal (as every school kid knows), we actually aren’t that much more certain. For example, if 1 out of 2 users has a bad experience, we can be 90% confident the experience might be shared by between 12% and 88% of all users. That’s a range of precision of 76 percentage points. By adding one more user to break the tie, we can be 90% confident the problem will impact between 25% and 93% of all users (a range of precision of 68 percentage points). So when we go from 2 to 3 users, we are improving our precision by only 8 percentage points. Both ranges are still huge.
Conclusion
While watching 2 and 3 users is better than watching 1 or 0, I’m not willing to say watching 2 or 1 is worse than watching none. Watching one user means there is no way to assess the many different ways users could interact with a product. While diverse usage may be an important thing to observe, identifying and fixing usability problems is usually equally as important.
Watching just a single user still provides information on the impact of an interface problem. Over time, if stakeholders are consistently watching a single random user in each usability study, odds are they will be more likely to see common problems than freak occurrences. In any given study they will have a good chance of being misled by an unusual experience, but overtime, even single-session sampling will converge onto the most common problems.
If a stakeholder has such a track-record of poorly interpreting data, I suspect forcing more observation will just lead to forcing more misinterpretation. So while there’s probably not much harm in having a plurality rule, I’m still convinced that some is better than none.
Thanks to Tomer Sharon and Jim Lewis for discussing the merits of this approach.

")
")