There has been a bit of an explosion in remote usability testing tools of late. Some of these companies also offer to recruit and provide you with users who are paid to take your usability test (Usertesting.com, Feedback Army and EasyUsability to name a few). These services allow for quick (almost immediate) feedback from users. Data is gathered quickly via the internet as users are asked to complete tasks, comment on designs and answer questions. For very little money you can have someone from almost anywhere in the world essentially complete a usability test. But is it too good to be true? Can we really trust the data from panels of users who essentially have a part-time job taking usability tests?
Recruiting, scheduling, compensating and taking the time to sit in an expensive lab to watch users attempt tasks can take months of planning and executing as well as cost thousands of dollars. There will always be a need for face-to-face, or at least synchronous remote usability testing. However there are certainly tasks that lend themselves well to these fast feedback sources such as finding out how many users can locate a product from a website homepage.
Earlier I examined the data between remote unmoderated testing and lab-based testing. The results were encouraging and suggested that completion rates and satisfaction scores from an unmoderated test were very similar to a lab based test and statistically indistinguishable. There were statistically significant differences between the groups for task-time data. In that comparison both sets of users were volunteers, either known and observed, or pulled from within the semi-trusting confines of a large company. Would the results fall apart if we used a pool of users we know little about to go off and complete the same tasks?
The Concern: Professional Usability Test-Takers are Biased
It’s reasonable to be skeptical about a cheap and readily available source of user feedback. The biggest concern is that these professional testers are unrepresentative of a general user population (more web-savvy, younger, etc.) and will therefore provide unreliable data. We could think of them as being in it just for the money—usability mercenaries if you will.
On the other hand there already is a certain self-selection bias with lab-based usability test participants. Not everyone is willing and has the time to spend a few hours during the workweek to drive to and participate in a test. These users don’t necessarily match the total user-population makeup, but probably represent a subset. So selection bias isn’t unique to professional test-takers or to usability tests in general (it is also a certain person who volunteers to take a poll or participate in a clinical trial).
It seems there is a different sort of selection bias with professional usability testers than with those willing to participant in lab-based tests. Remote testing platforms allow you easier access to users who normally couldn’t or wouldn’t commit time to a lab-based test. It is not clear to me that one bias is always worse than the other. For that reason I set up an experiment to find out if we could get similar data on an application intended for a general population from users who get paid to take usability tests compared to lab-based users.
The Control
Last year I recruited 12 colleagues and friends to perform five tasks on the Budget.com rental car website. They all came into a usability lab where I personally watched and recorded data for all participants. Their only qualification was that they use the web and have rented a car before. They received a $5 gift-card for the 1.5 hours of their time. This was part of the CUE-8 workshop at UPA 2009, so I’ve already seen that my results corroborated by other teams.
The Test
I recruited my own set of professional users using different public venues on the Internet and compensated each user for their time. The only qualification here was that users were from the US. One complication I’ve learned with recruiting online users is you can’t ask them to do too much or you’ll just get people rushing through the questions to get compensated. So I split my usability test up into two tests, each containing just one task and a few multiple choice questions. Out of the five tasks I observed in the lab, I picked two of the most informative: “Find the price of a rental car (Price)” and “Determine if you were liable for repairs to the rental car with Loss Damage Waiver protection (LDW).” The tests were unmoderated sessions performed while users were online.
The Results
I obtained data from 26 users in total (12 and 14 on each task respectively) then combined those results and compared the data to my lab-based results from last year. Completion rates and SUS scores (System Usability Scale) were virtually identical (and statistically indistinguishable) between the lab-users and professional users. Figures 1 and 2 below show the means and 95% confidence intervals for these two metrics. The graphs were generated using the EasyStats Package.
Completion Rates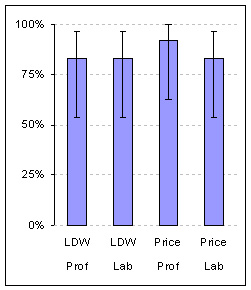 |
System Usability Scale (SUS) Scores 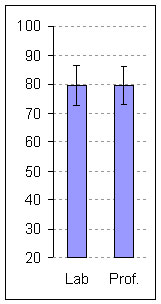 |
| Figure 1: Average completion rates and 95% Confidence Intervals by task and user-type. Average completion rates were identical for the LDW task and only slightly different and not statistically different for the price task (Prof= Professional Users; Lab= Lab Based Users). | Figure 2: Mean SUS scores and 95% Confidence Intervals. SUS Scores were virtually identical and statistically indistinguishable between users-types (Prof= Professional Users; Lab= Lab Based Users). |
Post task ratings were almost identical on one task and modestly different on the other, although not statistically different (p >.10).
Mean task times differed by more than 40% for both tasks (p < .01). Figures 3 and 4 below show the means and confidence intervals for these two metrics. The graphs were generated using the EasyStats Package.
Post Task Ratings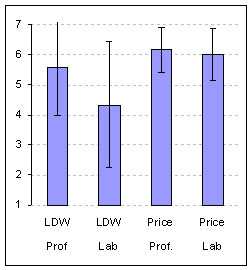 |
Task Time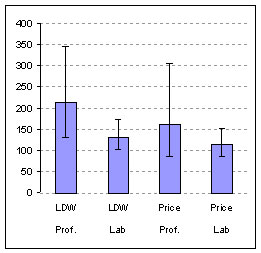 |
| Figure 3 : Average Post-Task ratings of difficulty and 95% confidence intervals by task and user-type. Average ratings were almost identical for the Price task but differed for the LDW task (p >.10) (7 = very easy; 1= very difficult) (Prof= Professional Users; Lab= Lab Based Users). | Figure 4: Mean Task Times (log-transformed) and 95% Confidence Intervals by task and user-type. Mean task times differed by more than 40% for both tasks (Prof= Professional Users; Lab= Lab Based Users) |
Conclusions
These results are similar to those between the lab-based and remote unmoderated test from the CUE-8 data using the non-professional users.
That is, we see very similar SUS scores and completion rates but different task times, with professional users taking more time to complete the tasks and having higher variability than the lab-based users.
This data suggests professional users will likely generate results similar to both lab-based tests and unmoderated tests with controlled users for satisfaction scores and completion rates. Task-times continue to show a major difference. This means that you will get different task times in a lab than when using professional users remotely.
There are a number of reasons for the different times. First, users in a lab generally can’t answer the phone, check their email or go to the bathroom while time is running in the middle of a task. For remote professional users we really don’t know how diligent they are being, nor can we expect them to drop everything to complete the tasks. In this experiment I kept it to only a single task. Things would likely get worse with more tasks and longer tests. Second, you have to subtract the time it takes users to read your tasks and answer your questions as these are included in the total task times. Not all users take the same amount of time, which unevenly affect the times (both the magnitude and the variability). There are more sophisticated unmoderated tools which helps this problem but they don’t remove it entirely. It is unclear which of the two approaches generates the “correct” task time as both testing setups are contrived.
Can we trust these professional usability testers? The results thus far look promising. If you need a specialized group of users with a particular skill this service might not be for you (yet). But for testing websites intended for a general audience the use of professional testers appears to provide mostly reliable data quickly and for a fraction of the price. In general this should be a good thing for a community which strongly advocates user input but usually has a hard time obtaining it. Using professional test-takers can be one less barrier to more usable systems.


