 Why spend more time completing a task when it could be done in less time?
Why spend more time completing a task when it could be done in less time?
Users become very cognizant of inefficient interactions and this is especially the case with tasks that are repeated often.
Task time is the best way to measure the efficiency of a task and it is a metric that everyone understands.
Task Time Logistics
The familiarity of the task time metric masks some logistical complications.
- Do you count task-times from users that fail-the task?
- Do you train users prior to attempting the task?
- Do you assist users if they get stuck?
- How long should you wait let a user flounder ?
- Do you have users repeat the task?
- How do you handle times of users that take a really long time(outliers)?
- Do you measure users in a lab environment or can you use a remote unmoderated test?
- When do you start and stop the time?
- Should users think aloud?
- What about network lag-time?
- How stable of an estimate will a sample size of 10,50 or 300 users be?
- What about selection bias: are only satisfied users volunteering in tests ?
It’s easy to get overwhelmed by the logistical issues of measuring task-time. There are some good answers to these questions, but it begs the question about what the “real” task time is.
Different Methods, Different Times
Even when you have a clearly defined process for measuring task time you will face material differences when you vary methods.
For example, the task of finding the price of a mid-sized rental car for a specific location, date and time on a website like Budget.com. Here are the time estimates I got from three different approaches.
Moderated Lab Avg. Time: 114 sec: I had twelve users attempt this task in a usability lab while I watched from behind the glass. Eleven of them were able to complete the task successfully. It took these users an average of 114 seconds (the geometric mean) to complete the task.
Unmoderated Time: 162 sec: A few months later I had a different set of 14 users attempt the same task in a remote unmoderated study. This time ten users completed the task and their average time was 162 seconds (geometric mean). This average time is a whopping 42% longer than the lab study. Even at this small sample size there is reasonable evidence to conclude that the average times are different (p = .13). The website and task didn’t change but the method did.
KLM Predicted Time: 33 sec: Finally, we can predict how long it will take an experienced user to attempt the same task without making any errors using Keystroke Level Modeling.
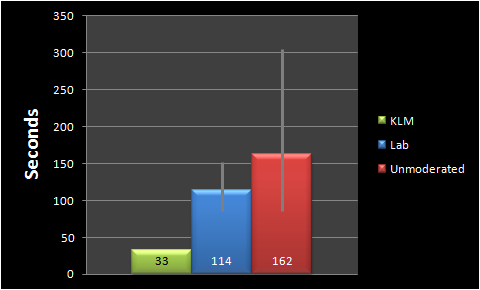
Figure 1: Estimates of task times from three different methods.
Error-bars represent 95% confidence intervals.
Which is the real task time?
The answer is they’re all wrong. They all contain some flaw–flaws in the methods, and flaws from sampling error for the two empirical approaches.
Users in a lab are being observed. They’re being more diligent and probably more efficient because they’re being watched (the Hawthorne Effect). So this time is probably too idealized. What’s more, users are less likely to be distracted during a task, and if they were, we’d stop the time or note this aberration.
In a remote unmoderated test, we can’t control what users are doing. They could be on the phone, sending emails or browsing the web while we ask them to complete our carefully constructed tasks. Professional users might also bring a certain mercenary bias to the tasks they perform.
The KLM time would only be realized for someone who rented a lot of cars on Budget.com, had no distractions, knew the airport code of the rental location and made no mistakes while finding the price.
Each method is wrong but informative
But don’t give up on measuring task time. Each method may be wrong but they are all informative.
Finding the one true task time can be a lengthy and unnecessary quest. It’s not the absolute time that matters as much as the time relative to a meaningful comparison like a competitor or new design.
For most usability tests, the point of finding the average task-time is to not just about having some estimate of how long it’s taking users. It’s about knowing whether your new design makes the lives of users a bit easier by cutting out inefficiencies.
For whatever the flaws of the method you chose, major improvements in efficiencies should overcome methodological flaws. Smaller differences will be difficult to detect using blunt methods, but interaction design is largely in the business of generating noticeable differences.
The trick is to be consistent. Use the same method in both comparisons. Don’t compare remote unmoderated task times with lab-based task times (or at least do so with caution).
Showing a 30% reduction in task time in a follow-up lab study, unmoderated study or KLM analysis all present compelling evidence that you’ve improved the efficiency of the task. The true reduction might be more modest, or potentially larger, but it is unlikely to be zero.
Oh and if you like Eminem’s affinity diagram (pictured above) you should see him moderate a usability test!

")
