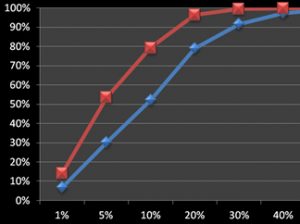
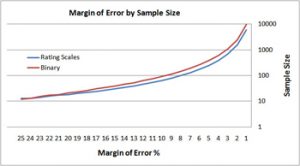
Is Observing One User Worse Than Observing None?
Seeing is believing. Observing just a handful of users interact with a product can be more influential than reading pages of a professionally done report or polished presentation. But what if a stakeholder only has time to watch two or just one of the users in a usability study? Are there circumstances where watching some