 How usable is a website?
How usable is a website?
While most usability activities involve finding and fixing problems on websites (often called formative evaluations), it’s good practice to know how usable a website is (often called a summative evaluation).
Obtaining a quantitative usability benchmark allows you to understand how design and functional changes impacted the user experience. We will cover this in detail at the Denver UX Boot Camp.
Here are the steps we follow in designing, conducting and analyzing benchmark usability tests.
Designing the Study
Identify the users to test: You probably have some idea about who the users or customers are that come to your website. The biggest variable we find is the users’ prior experience with a website. Users with more experience tend to perform better on tasks, have higher perceptions of usability, and have higher Net Promoter Scores.
Finding users: You can recruit users right off your website using a pop-up invite, email users from an existing customer list, or use a panel agency that finds users who meet your requirements (e.g. recently purchased a car). While it seems like pulling customers off your website or using a customer list will be the obvious lower-cost option, we often find users recruited this way are less motivated and less reliable to complete studies than panel provided users.
Defining the tasks: At the heart of a usability benchmark test are the tasks users will attempt. Don’t skimp on crafting the task-scenarios and take an iterative approach. You don’t want tasks to be too difficult and you don’t want to lead the users down each path. If possible, conduct a top-task analysis to find out what few tasks drive traffic to a website. Simulate these tasks in your usability benchmark study.
Comparative vs. stand-alone: Many projects start with the intent of just measuring a single website’s usability (stand-alone), but one of the first questions we get asked when presenting the results is how to interpret them: are they good or bad? When tasks have really low completion rates (<30%), it’s obvious there is a problem, as most users can’t complete the tasks. When the completion rates are higher (>60%) it becomes less obvious. Having users attempt the same tasks on a competitive or best-in-class website helps put task performance and perception metrics into context (comparative). This allows you to better differentiate between difficult tasks and a difficult experience.
Benchmark studies should be conducted regularly. For example: they should be conducted annually, semi-annually or after design changes have been made. Once you have run a benchmark study once, you’ll have the best comparable data for subsequent studies, so even stand-alone studies will have a comparison set.
Task metrics: The fundamental usability metric is task-completion. If users can’t complete the top-tasks on your website, not much else matters. But you’ll want to collect more than just this measure of effectiveness. You should plan on collecting task-based measures of efficiency (time-on-task) and satisfaction (post-task and post-test questionnaires). There are a number of other key usability metrics to consider, depending on the goals of the study.
Test metrics: You’ll also want to include measures of overall impressions of the website, typically asked after the study is completed. We use the SUPR-Q, which includes standardized measures of usability, credibility, loyalty and trust. Other popular measures include the Net Promoter Score and the System Usability Scale.
Sample Sizes: It’s a perplexing question for many. The sample size you need depends on a few variables, mostly the study type and metric. When doing a comparative study, the size of the difference you want to detect is the main variable to consider. For example, the sample size needed to detect a 20-percentage-point difference in completion rates, assuming a 90% confidence level and 80% power, with different users in each group, would require a sample size of 75 in each group, or 150 total users. More information on finding the sample size for a benchmark study.
For better or worse, internal politics often plays more of a role in sample size selection than the statistics. So while the math might recommend a sample size of 75, testing 100 may just sound better and generate more study buy-in from stakeholders, even if the difference in the level of precision is negligible.
Conducting the Study
Software: It’s hard to conduct a benchmark study without some online software, most of which isn’t cheap. Here are some options.
Low/No Cost /Low Features
The most cost-effective thing you can do is use free survey software like Survey Monkey. You can show participants task descriptions, ask them to attempt them by opening a new browser window, and then have them answer some questions about the experience as well as assess task completion by asking a validation question. You probably won’t have reliable measures of task-time, and you can’t be sure users are putting in the right effort to solve the tasks. Surprisingly though, this low-cost method can deliver insights and reliable perception metrics. Self-reported task completion rates will be high, as users tend to be over-confident in their ability.Medium Cost / Medium Features
Loop11‘s unmoderated usability testing tool costs $350 for a single study, and it offers the ability to present users custom tasks, record task-times, and collect post-task metrics and post-test questions.If you are looking to test fewer than 50 users, then usertesting.com’s panel of users and tool may work. There’s no cost for the software, just the cost per user (around $50). Usertesting.com is adding more metrics to their platform, but currently, you can present users tasks, ask them open- and closed-ended questions, see what they are seeing, and have the users articulate their thoughts—which are usually very insightful for identifying improvements. Because you have a record of everything the user sees, you can essentially derive task-completion, task-time and questionnaire data from watching the videos. This approach will take more time. In most of our benchmark studies, we supplement our larger sample panel data with 5-10 users from Usertesting.com.
High Cost/High Features
UserZoom offers the most comprehensive solution for testing website usability and has become the industry standard for large-scale benchmark studies. You can use skip-logic, randomization and profiles for presenting the tasks. In addition to the standard task-based metrics, you also have the ability to collect click-paths, heat-maps and even playback video recordings of the users attempting the tasks. This last feature often justifies the cost of UserZoom alone, as you have a good record of both the metrics (the output) and what the users were doing (the input). We use UserZoom for most of our benchmarking studies.
Pilot: Plan to run a few users through your programmed study to work out the kinks in both the study structure and the tasks themselves. It usually takes us two or three tries to get the tasks to the point where they aren’t too leading for users, but aren’t so hard that too many users are unable to complete them or run out of time.
Field the Study: For most unmoderated benchmark studies, plan on having the study open for users to complete for five days. For smaller sample sizes (<100) and shorter studies, it can be done more quickly, but it never hurts to have a few extra days in case you encounter problems in recruiting or need to stop the study and make changes.
Analyze the Results
There will be more data than you can handle if you use a solution like Loop11. The examples below come from a comparative study between Budget.com and Enterprise.com. We start by analyzing the task-performance metrics of completion rates, task times, task-difficulty and a combined measure of usability (the Single Usability Metric SUM).
The graphs include confidence intervals (yellow error bars) to show the level of precision in our metrics (click to enlarge the images).
 |
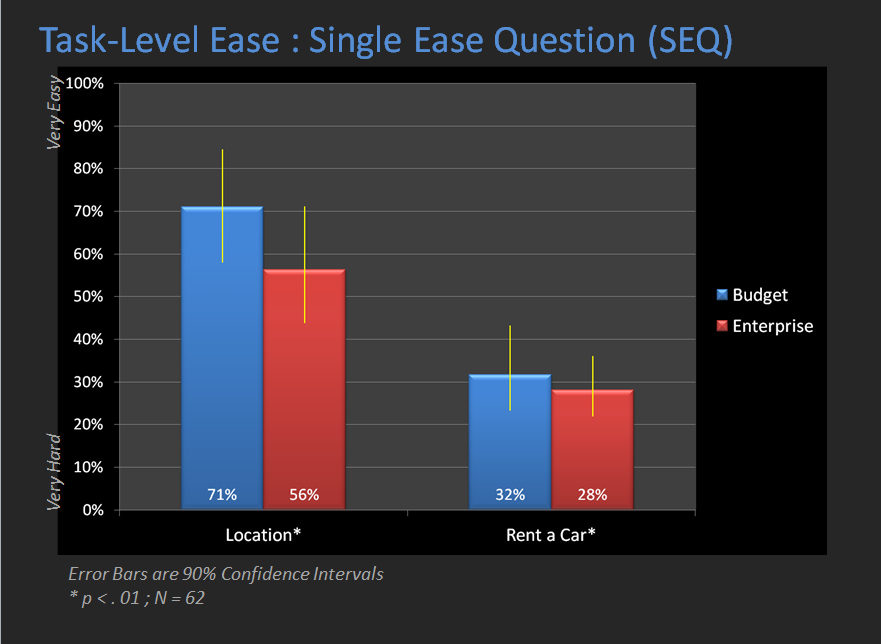 |
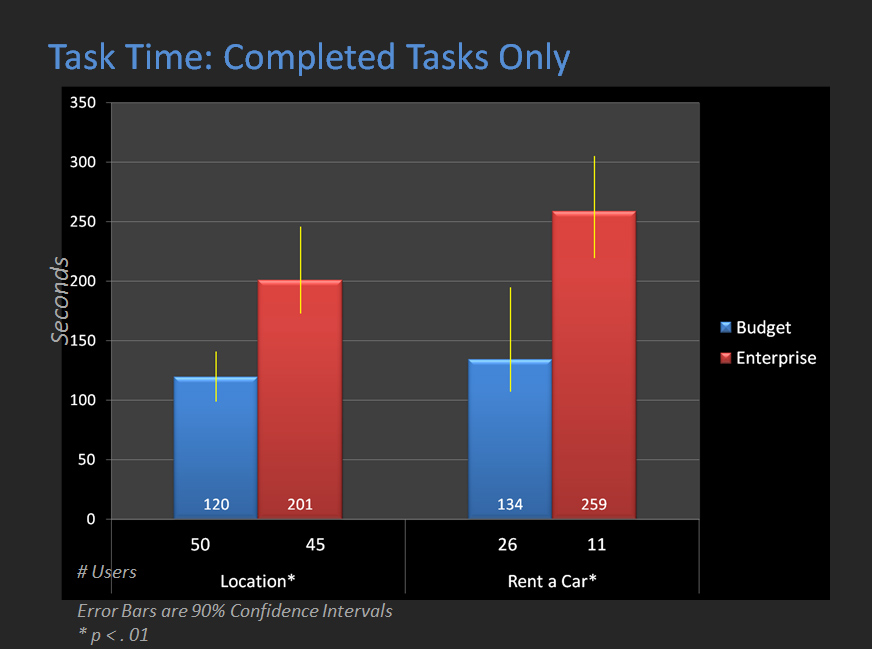 |
 |
Then we summarize the overall attitudes. The examples below are the SUPR-Q scores and Net Promoter Scores for both websites.
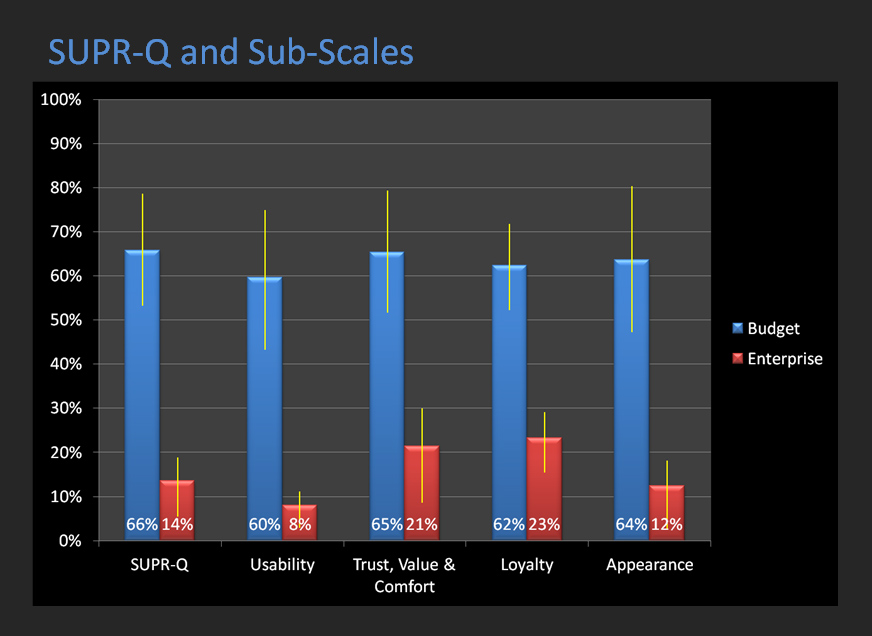 |
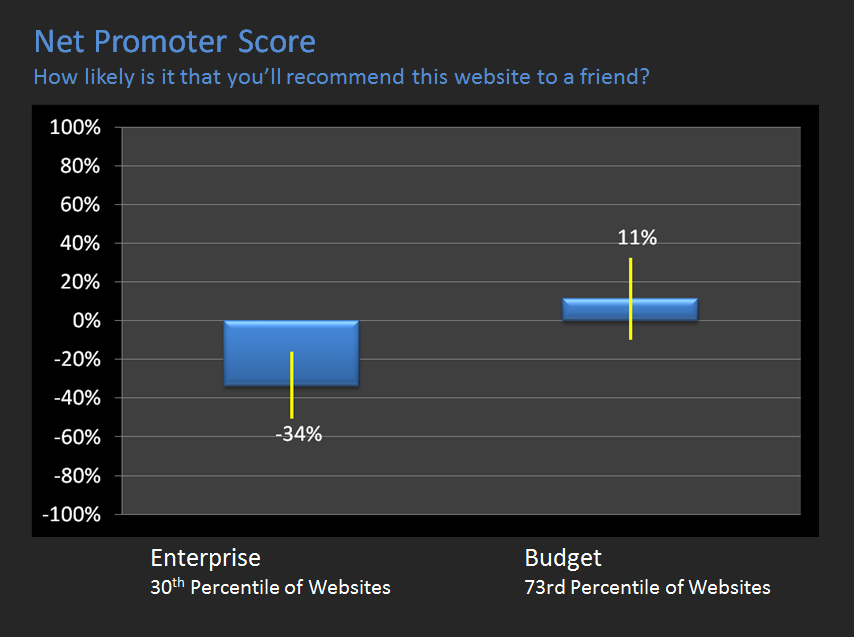 |
It’s often not until we have all the task and test-level metrics together that we start seeing a story emerge. Sometimes it’s one task with low performance that needs extra analysis, and other times it’s low SUPR-Q scores or Net Promoter Score.
Finally, we dig into the “why” by examining the verbatims, clickmaps, video replay and any Usertesting.com videos to understand what’s driving the numbers. While identifying fixes is not typically the primary goal of benchmark usability tests, we document the major usability problems and recommend some fixes.
The benchmarking effort isn’t trivial, so hopefully many of the root causes of the problems have been addressed before launching a follow-up study. Committing to regularly scheduled benchmark studies helps make everyone accountable for website usability and prioritizes the never-ending list of design and feature changes.