 The System Usability Scale (SUS) is a popular measure of perceived usability.
The System Usability Scale (SUS) is a popular measure of perceived usability.
It’s a 10-item questionnaire scored on a 101-point scale and provides a measure of a user’s perception of the usability of a “system.”
A system can be just about anything a human interacts with: software apps (business and consumer), hardware, mobile devices, mobile apps, websites, or voice user interfaces.
By itself though, the SUS can be difficult to interpret. Is a score of 50 average or good? Is 90 achievable or unrealistic?
To make any measure more meaningful, including the SUS, it needs to be compared to something. With the benefit of 30 years of usage and data from over 10,000 responses and hundreds of products, you can interpret your SUS in at least five ways. Figure 1 summarizes these approaches and are explained in detail below.
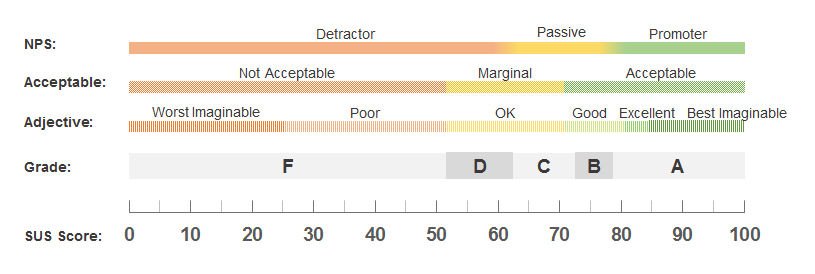
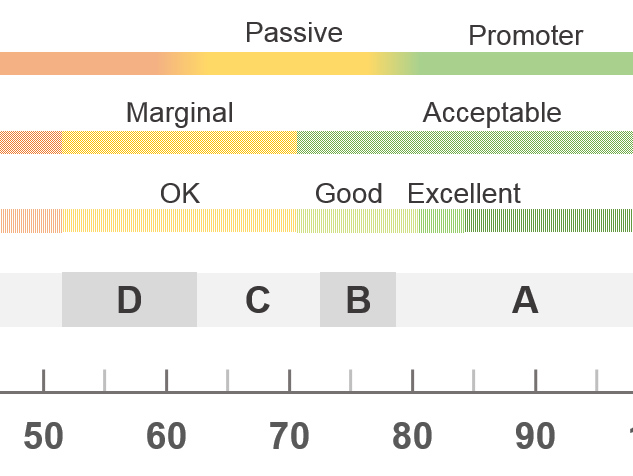
Figure 1: Grades, adjectives, acceptability, and NPS categories associated with raw SUS scores.
1. Percentiles
Raw SUS scores can be converted into percentile ranks. Percentiles are the same approach pediatricians use to tell whether an infant is over or underweight. We took the large dataset of SUS scores and “normalized” them to allow for percentile ranks. Percentile ranks tell you how well your raw score compares to others in the database. Figure 2 shows the percentile ranks for common raw SUS thresholds.
The average score (at the 50th percentile) is 68. That means a raw SUS above 68 is above average and below 68 is below average. A SUS of 75 is at the 73rd percentile (scoring better than 73% of the scores in the database). A raw SUS of 52 falls at the 15th percentile (scoring worse than 85% of the scores in the database).

Figure 2: SUS on a curve with percentile ranks and grades.
2. Grades
Closely related to percentile rankings are grades; the same type of grading system you likely had (and maybe hated) in school. Grades range from A, which indicates superior performance, to F (for failing performance), with C indicating “average.” While grade inflation seems to have happened over the last few decades (with many students getting all As and Bs), Jim Lewis and I made this grading scale on a curve. The curve more evenly distributes the grades to match the normal curve (hence the normalization process used for percentiles). This can be seen in both Figures 1 and 2.
3. Adjectives
Building on the idea of using words instead of numbers to describe an experience, Bangor et al. associated 1,000 SUS scores with a 7-point adjective scale. The scale contains adjectives including “Good,” “OK,” and “Poor”—words users loosely associate with the usability of a product.
For example, they found scores above 85 are associated with “Excellent.” “Good” was just above average at 71 and “OK” for scores at 51. (The adjective “Awful” wasn’t significantly different than other adjectives and was excluded.) Both Table 1 (end of the article) and Figure 1 include the remaining six adjectives and their corresponding SUS score. Some more recent research is suggesting “Fair” may be a better adjective than “OK,” which connotes an acceptable experience (when it is at best marginal).
4. Acceptability
Another variation on using words to describe the SUS is to think in terms of what’s “acceptable” or “not acceptable.” Bangor et al. (2008) assigned these terms for when the SUS was well above average or well below average. Acceptable corresponds to roughly above 70 (above our average of 68) and unacceptable to below 50 (closely corresponding to our designation of scores lower than 51.6 with a grade of F). They designated the range between 50-70 as “marginally acceptable,” which encompasses a range from C to D in our curved grading scale. Table 1 and Figure 1 also show these levels of acceptability.
5. Promoters and Detractors
We’ve consistently seen a strong correlation between the SUS and the Net Promoter Score. On average, the SUS explains between 30% and 50% of the variation in users’ likelihood to recommend. The NPS designates three classes of recommenders based on their responses to the 11-point (0 to 10) likelihood to recommend question. Promoters score 9 and 10; passives, 7 and 8; and detractors, 6 and below. While promoters (as the name suggests) are most likely to recommend the product/website/app to a friend, detractors are more likely to discourage rather than recommend.
We have both NPS and SUS data from 4,664 respondents and computed the average SUS for each of these classifications of recommenders. Figure 3 shows this relationship (R-Sq = 42%). To achieve a Promoter classification, a SUS score needs to be reasonably close to 81 on average (which is a high bar). Detractors are associated with an average SUS of 53 and below and Passives are the scores in between (averaging 70). The graded yellow on the passive bar in Figure 1 indicates the uncertainty from using this approach. A future analysis is needed to better establish the boundaries between categories.
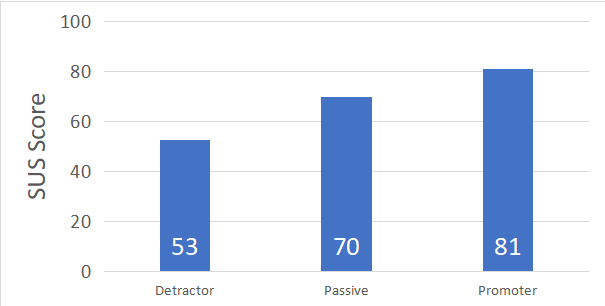
Figure 3: Average SUS scores associated with different NPS classes from 4,664 respondents.
Table 1 provides the values from the graphic in Figure 1.
| Grade | SUS | Percentile range | Adjective | Acceptable | NPS |
|---|---|---|---|---|---|
| A+ | 84.1-100 | 96-100 | Best Imaginable | Acceptable | Promoter |
| A | 80.8-84.0 | 90-95 | Excellent | Acceptable | Promoter |
| A- | 78.9-80.7 | 85-89 | Acceptable | Promoter | |
| B+ | 77.2-78.8 | 80-84 | Acceptable | Passive | |
| B | 74.1 – 77.1 | 70 – 79 | Acceptable | Passive | |
| B- | 72.6 – 74.0 | 65 – 69 | Acceptable | Passive | |
| C+ | 71.1 – 72.5 | 60 – 64 | Good | Acceptable | Passive |
| C | 65.0 – 71.0 | 41 – 59 | Marginal | Passive | |
| C- | 62.7 – 64.9 | 35 – 40 | Marginal | Passive | |
| D | 51.7 – 62.6 | 15 – 34 | OK | Marginal | Detractor |
| F | 25.1 – 51.6 | 2– 14 | Poor | Not Acceptable | Detractor |
| F | 0-25 | 0-1.9 | Worst Imaginable | Not Acceptable | Detractor |
Table 1: Percentiles, grades, adjectives, and NPS categories to describe raw SUS scores.
Thanks to Jim Lewis for commenting on an earlier draft of this article.