 AI can “watch” videos.
AI can “watch” videos.
It can even generate a list of problems. In some cases, these problem lists seem to be reasonably consistent (reliable).
But consistency is not accuracy. Are these real problems or just sophisticated AI slop generated consistently by autocorrect for video?
How can we know? One way to find out is to compare the AI problem lists to those created by trained UX researchers.
Are the problems an AI finds the same problems a UX researcher would find?
In this article, we move from reliability to validity by comparing the problems identified by AI to those found by human UX researchers reviewing the same video.
Humans vs. AI: Same Video, Same Task
For this study, four UX researchers at MeasuringU independently reviewed a roughly six-minute usability test video and created lists of observed usability problems. The primary evaluator had over 40 years of experience coding usability problems, while the other three, at the time of the study, each had less than a year of experience. The video they watched was the same one reviewed by two LLMs in our previous assessment of AI reliability (ChatGPT-5.4 Thinking and Gemini 3 Flash Thinking, four runs per LLM to assess reliability). The participant’s task was to use OpenTable.com to book a reservation:
“Make a reservation for four people at a sushi restaurant in Denver, CO tomorrow anytime after 5:00pm. Make sure the restaurant you select is not at the lowest or highest price point. Of the restaurants that fit these criteria, look at their overall rating, customer reviews, and photos to select the one that is the most appealing to you. Go as far as you can in the reservation process until you are asked for your personal information or account details. DO NOT fully confirm the reservation. Write down the restaurant name and the time of the reservation. You will be asked about this information after the task.”
The directions for the human evaluators matched the prompt given to the LLMs:
“During a usability test, the facilitator must keep track of participant behaviors as they navigate through tasks on a website, mobile app, software program, etc. We’d like you to watch a video of a usability test where participants were asked to book a table at a Sushi restaurant. As you’re watching, please look for problems the participant has while attempting to complete the task. For example, you can document the path users take, describe issues they encounter as well as what on the website might be causing problems.”
Coding and Matching Problems
The four researchers independently created their problem lists. The senior researcher (Evaluator 1) then reviewed, matched, and consolidated the problems as shown in Table 1.
| Prob # | Human Evaluators Problem List | Eval 1 | Eval 2 | Eval 3 | Eval 4 |
|---|---|---|---|---|---|
| 1 | Complex search field with placeholder text and unexpected behaviors significantly delayed user who selected sushi from search bar dropdown but for Dallas (default) instead of Denver | ||||
| 2 | Odd display of email addresses upon click in search field | ||||
| 3 | Avoided search field and looked in filters to try to change location | ||||
| 4 | Entering Denver in search field lost previous selection of sushi as cuisine | ||||
| 5 | Scanning through 86 cuisines is effortful, then top that off by sushi not being in the list | ||||
| 6 | Surprised when typing sushi into search field did not lose current location | ||||
| 7 | Participant seemed to miss price point filter—sorted on ratings and examined price points in descriptions | ||||
| 8 | Participant wanted to change sort to lowest rating first but not an option | ||||
| 9 | Despite having selected 5pm at start of process user needed to reselect it later | ||||
| Total |
Table 1: Human evaluators’ problem list.
Nine total problems were identified, none of which was classified as a false alarm by Evaluator 1. Four problems (3, 4, 5, and 6) were identified by all four UX researchers. Two problems (1, 8) were identified by three evaluators, one problem (7) by two evaluators, and two problems (2, 9) by one evaluator.
High Reliability for Humans
With the consolidated problem list, we computed the any-2 agreement across all pairs of evaluators as shown in Table 2. Any-2 agreement accounts for interrater reliability of the different problem lists better than Kappa when assessing agreement.
| Any-2 | Eval 1 | Eval 2 | Eval 3 | Eval 4 |
|---|---|---|---|---|
| Eval 1 | x | 57% | 56% | 63% |
| Eval 2 | 57% | x | 63% | 71% |
| Eval 3 | 56% | 63% | x | 88% |
| Eval 4 | 63% | 71% | 88% | x |
Table 2: Any-2 agreement for the human evaluators.
The average any-2 agreement across all pairs was 66%. Based on our data, the general rule of thumb for interpreting any-2 agreement is that 50% is typical, 25% is low, and 75% is high.
That means the reliability of the human evaluators was relatively high, likely because some of the usability problems in the list were quite salient (4/9 identified by all four evaluators, 6/9 identified by at least three evaluators).
In our previous study of AI analysis, the reliability of ChatGPT was relatively low (31%) while Gemini was above average (57%).
Agreement Was Low Between AIs and Humans
We created consolidated problem lists for ChatGPT and Gemini by combining results across four runs and matching them to the human-identified problems. Problems labeled “ChatGPT” or “Gem” are unique to those systems. Problems without labels were also found by humans.
ChatGPT Validity
Table 3 shows the combined problem list for the four runs of ChatGPT. It included five problems from the human list and seven unique problems. Table 4 shows the human by ChatGPT any-2 agreement.
| Prob # | ChatGPT Problem List | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|---|
| 1 | Complex search field with placeholder text and unexpected behaviors significantly delayed user who selected sushi from search bar dropdown but for Dallas (default) instead of Denver | ||||
| 4 | Entering Denver in search field lost previous selection of sushi as cuisine | ||||
| 4b-ChatGPT | Filters not helpful | ||||
| 5 | Scanning through 86 cuisines is effortful, then top that off by sushi not being in the list | ||||
| 6 | Surprised when typing sushi into search field did not lose current location | ||||
| 6b-ChatGPT | Search results for sushi included many non-sushi restaurants | ||||
| 6c-ChatGPT | Weak presentation of cuisine information in search results | ||||
| 7 | Participant seemed to miss price point filter—sorted on ratings and examined price points in descriptions | ||||
| 7b-ChatGPT | Sorting by highest rated put many non-sushi restaurants at the top of the list | ||||
| 8b-ChatGPT | UI pushes browsing without good decision support | ||||
| 10a-ChatGPT | Selected result labeled seafood instead of sushi | ||||
| 10b-ChatGPT | Task not completed because did not reach reservation form | ||||
| Total |
Table 3: ChatGPT evaluations problem list (problems tagged with ChatGPT were not reported by humans).
| Any-2 | ChatGPT 1 | ChatGPT 2 | ChatGPT 3 | ChatGPT 4 |
|---|---|---|---|---|
| Eval 1 | 18% | 33% | 33% | 0% |
| Eval 2 | 9% | 22% | 22% | 0% |
| Eval 3 | 25% | 27% | 27% | 0% |
| Eval 4 | 27% | 30% | 30% | 0% |
| Mean: | 19% |
Table 4: Any-2 agreement for human with ChatGPT evaluations.
Gemini Validity
Table 5 shows the combined problem list for the four runs of Gemini. It included four problems from the human list and five unique problems. Table 6 shows the human by Gemini any-2 agreement.
| Prob # | Gemini Problem List | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|---|
| 4 | Entering Denver in search field lost previous selection of sushi as cuisine | ||||
| 5 | Scanning through 86 cuisines is effortful, then top that off by sushi not being in the list | ||||
| 5b-Gem | Participant used Ctrl-F to search page for "sushi"—not found | ||||
| 7 | Participant seemed to miss price point filter—sorted on ratings and examined price points in descriptions | ||||
| 7b-Gem | Participant chose highest price tier | ||||
| 8 | Participant wanted to change sort to lowest rating first but not an option | ||||
| 9b-Gem | Seating options only presented after selecting time | ||||
| 9c-Gem | Set time to 5:10 | ||||
| 10a-Gem | Selected result labeled seafood instead of sushi | ||||
| Total |
Table 5: Gemini evaluations problem list (problems tagged with Gem were not reported by humans).
| Any-2 | Gem 1 | Gem 2 | Gem 3 | Gem 4 |
|---|---|---|---|---|
| Eval 1 | 29% | 29% | 25% | 29% |
| Eval 2 | 33% | 33% | 50% | 33% |
| Eval 3 | 38% | 22% | 50% | 38% |
| Eval 4 | 43% | 25% | 57% | 43% |
| Mean: | 36% |
Table 6: Any-2 agreement for human with Gemini evaluations.
We found the poorest agreement between human and ChatGPT evaluations (19%). Agreement between human and Gemini evaluations (36%) was substantially higher but still relatively low.
These agreement rates account for problems AI found that humans didn’t. We treated AI-discovered problems as if they were real (for now), but they could have been false positives (an error humans make, too). What is a “real” problem? That’s been a long-standing research question. For now, we’re relying on the senior researcher to determine the real problems. That human-verified problem list is how we’ll evaluate the AIs.
Did AI Find the Same Problems as Researchers?
We can use the human-generated and verified problem lists as the “gold-standard” and assess AI’s “hit-rate” as another measure of validity beyond any-2 agreement. The four human evaluators identified nine usability problems. ChatGPT identified five, and Gemini identified four. Figure 1 shows the problems identified by human evaluators and how well both AI models identified them. We consolidated the runs, counting a problem if it was found at least once across any of the four runs.
Four of the problems were found by all four researchers, suggesting they were more salient problems. ChatGPT uncovered three of these four, and Gemini uncovered two.
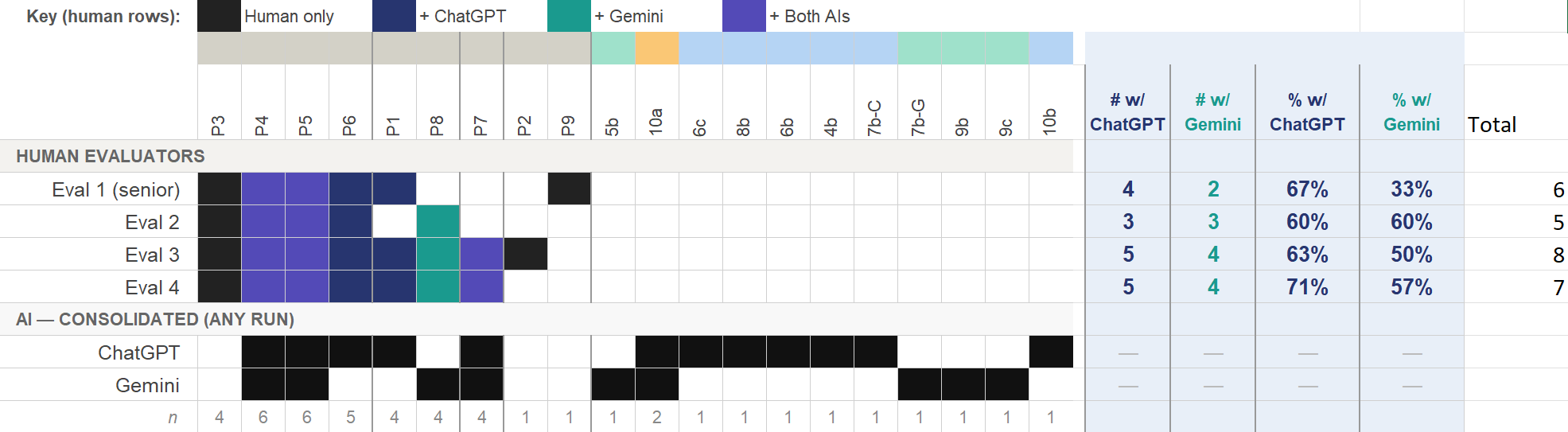
Figure 1: How well AI models found usability problems identified by researchers.
Comparing AI to a pooled set of problems from four researchers may not be a fair comparison. We should also consider how well AI does compared to each individual researcher. Figure 1 shows that, for example, ChatGPT identified four of the six problems identified by the senior evaluator. Gemini uncovered two of the six problems. Across each of the four evaluators, ChatGPT identified between 60% and 71% of the usability problems, and Gemini identified between 33% and 60% (see right side of Figure 1).
Figure 2 is a Venn diagram that shows the overlap in problems found between both AIs and between AIs and humans. AIs generated eleven problems not identified by any of the four researchers, and there were three problems identified by humans only. ChatGPT came up with seven new ones and Gemini five (they agreed on one of the problems).
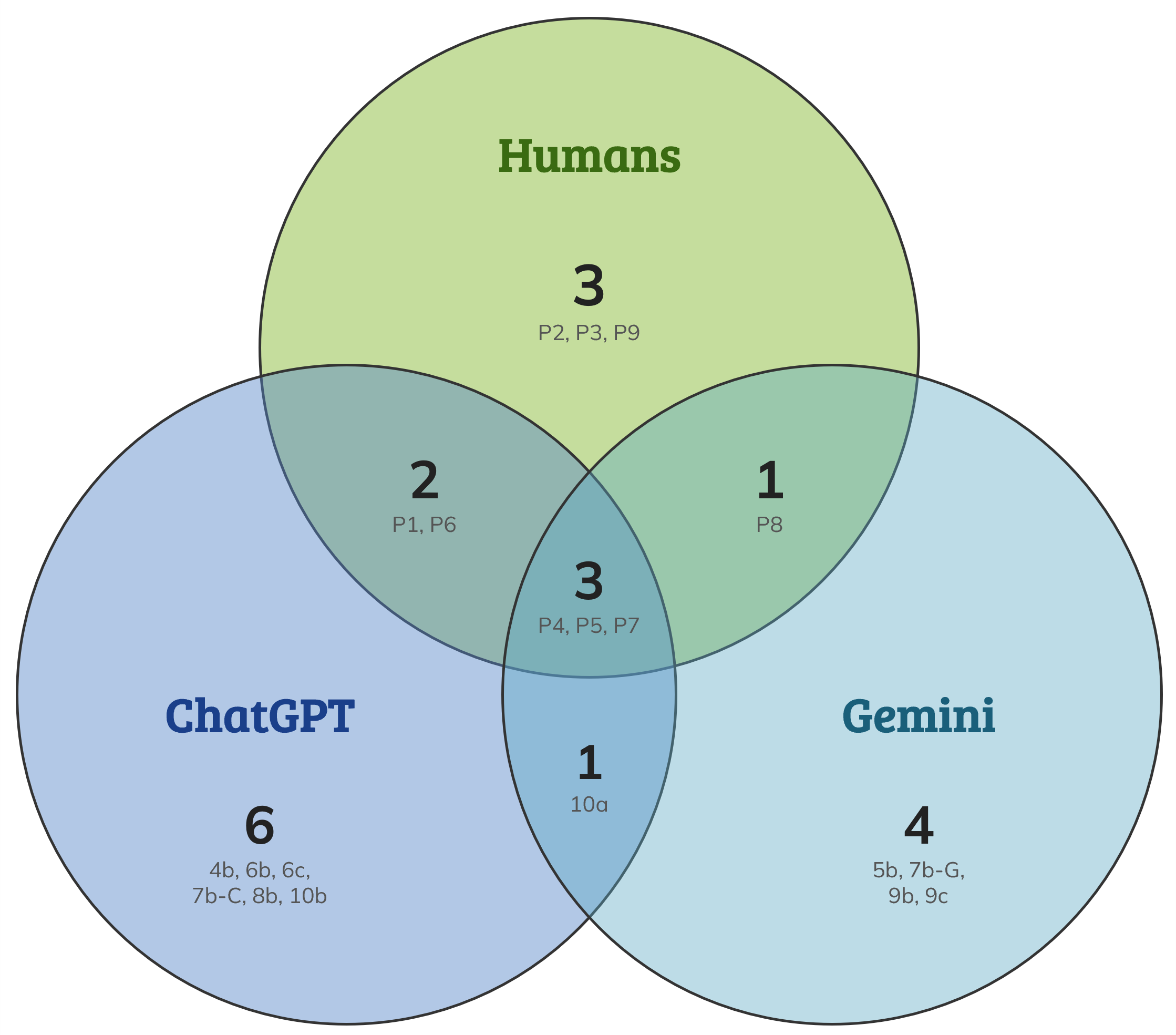
Figure 2: Venn diagram of usability problem discovery by humans, ChatGPT, and Gemini.
AIs generated more new problems (eleven) than the total list generated by four humans (nine). It’s not clear whether these additional AI-identified problems represent true usability issues that humans missed or are false positives/hallucinations. We’ll dig into the qualitative difference on those problems in an upcoming article. What is clear is that all these additional problems likely require a human’s time to review them.
Summary and Discussion
Building on our previous research into the reliability of AI usability problem discovery, we investigated the validity of AI evaluations by seeing whether AI and human evaluators agree on which problems they find. Using the same video, task, and prompt, four UX researchers and two LLMs (ChatGPT and Gemini, four runs each) independently produced problem lists. Our key findings:
Humans had higher within-group reliability than the LLMs. Any-2 agreement among human evaluators was 66%, well above the 31% we previously reported for ChatGPT and somewhat above Gemini’s 57%.
Agreement between humans and AI was low. The human-ChatGPT any-2 agreement was just 19%, the lowest we observed. Human-Gemini agreement was better at 36%, but still below the typical human baseline of 47%. Low agreement means AI and humans often flag different problems when watching the same video with known usability issues.
AI identifies roughly half the problems humans find. ChatGPT identified five of the nine human-verified problems, and Gemini identified four. Of the four problems that were identified by all human evaluators, three were identified by both AIs. The nine problems were a vetted compilation from all four human evaluators. When we limited the comparison to individual evaluators, ChatGPT matched 60–71% of each researcher’s list, and Gemini matched 33–60%. The AIs didn’t find all the problems reported by humans, but depending on the evaluator(s), they can find more than half of them.
AI generates more new problems than humans do. The two AIs together produced eleven problems that no human identified (at least from one video), which is more than the entire human problem list of nine. ChatGPT contributed seven unique problems and Gemini five, with one shared between them. It’s not yet clear whether these represent real usability issues that trained researchers missed or are false positives (we’ll explore these possibilities in an upcoming article).
AI-only problems create a new validation burden. Someone has to determine which AI-generated problems are real, and that means a human reviewing each one. If AI is being used to save time, the volume of unverified AI-generated problems may offset much of those savings. Whether the tradeoff is worth it likely depends on how many of those problems turn out to be real, again something we’ll examine in a follow-up.
In our next article, we shift from this quantitative comparison to a qualitative examination: using the video as ground truth, we ask whether the AI-only problems reflect events that actually happened or whether the LLMs hallucinated issues that never occurred.