 Do you have a Netflix subscription? Do you have a Hulu subscription?
Do you have a Netflix subscription? Do you have a Hulu subscription?
Which of the following services do you have a subscription to?
- Netflix
- Hulu
- Disney+
- Peacock
- HBO Max
Will you get a different percent of Netflix or Hulu selections if you ask the first form of the question compared to the second one? If you do, is it a large difference or a trivial one?
This article reviews the published literature on the possible impacts these question formats may have on responses.
Background
Core aspects of conducting UX research include finding the right participants (screening) and understanding participants’ attitudes and prior behavior. For example, you might request self-reports of prior experiences (e.g., products purchased, stores visited) or ask what product features your participants believe to be crucial (e.g., top tasks).
To accomplish this, it’s common in surveys to present grids of options in which respondents use checkboxes to indicate which options apply to the question being asked (Figure 1), commonly referred to as “Check-all-that-apply” (CATA) or “Select-all-that-apply” (SATA).

Figure 1: Example of a select-all-that-apply item grid (created with MUIQ®).
An alternative format is the forced choice grid where respondents must explicitly select yes or no for each option presented in a grid (Figure 2).
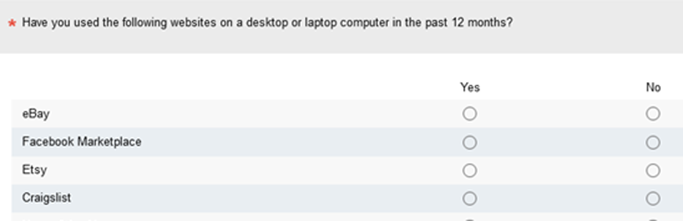
Figure 2: Example of a forced choice yes/no item grid (created with MUIQ).
It is also possible to present forced choice items as a series of yes/no items (as shown in Figure 3), which take up more space compared to a grid because the question is repeated instead of appearing only once.
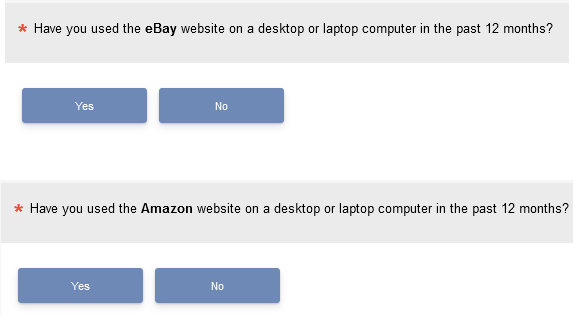
Figure 3: Example of a forced choice yes/no item series (created with MUIQ).
In 1982, Sudman and Bradburn hypothesized that requiring respondents to take an action for each option (forced choice) should result in a higher selection rate than the SATA format. They reasoned that failure to check an option in a SATA item could be due to causes other than the option not being applicable.
For example, respondents might unintentionally skip over the item or intentionally stop reviewing items before reaching the end of the list to get through the survey faster. Based on this rational analysis, they advised against using the SATA format and recommended using a forced choice grid (such as the one in Figure 2).
It seems plausible that the forced choice formats should produce more affirmative responses than selections in the SATA format, but such reasoning doesn’t provide insight regarding the magnitude of the difference or whether the forced choice format matters (grid vs. series).
Estimating these effects requires empirical investigation. Although many papers report the use of SATA (e.g., Ares et al., 2010; Parente et al., 2011), we found only a few published studies that compared SATA versus forced choice, which we review below.
Prior Literature
National Education Longitudinal Study of 1988
In 1994, Rasinski et al. (who worked on the 1982 article described above) published the first experiment that compared SATA and forced choice. They used data collected in the National Education Longitudinal Study of 1988.
A total of 2,210 high school students completed different versions of a paper-and-pencil survey about their experiences during high school. The primary independent variable of interest was the format (SATA vs. forced choice).
The experimental manipulation was applied to three items with 4, 12, and 20 response options (total of 36). Across the three items, the mean number of selections with the SATA format was 4.04; with the forced choice format the mean number of positive responses was 4.6.
One way to standardize these findings is to convert the mean number of selections to percentages by dividing them by the total number of 36 possible selections. With this manipulation, the mean of 4.04 becomes 11.2% and 4.6 becomes 12.8%, a difference of 1.6%.
Unsurprisingly, with a sample size of over 2,000, this difference is statistically significant (due to the power of the study), but whether it is large enough to be of practical significance is another question.
Undergraduate Experience at Washington State University
Smyth et al. (2006) manipulated SATA and forced choice formats in three surveys of the undergraduate experience at Washington State University. In the first survey, 1,800 respondents answered three items with a total of 36 response options; in the second survey, 3,004 respondents answered six items with 77 response options; and in the third survey, 3,045 respondents answered one item with 15 response options.
Across this series of surveys, there were 128 choices, with a mean selection rate of 3.56 for the SATA format and a positive selection rate of 4.53 for the forced choice format (statistically significant differences for all three surveys). Dividing these means by 128, the SATA selection percentage was 2.78%, and the forced choice positive selection percentage was 3.54%, a difference of about 0.8%.
In 2008, Smyth and colleagues conducted a similar online survey comparing SATA and a forced choice grid with a total of 64 choices across six items. They also collected similar forced choice data using telephone surveys, but we focused on the online results because it isn’t possible to collect SATA over the phone.
The total number of choices across the items was 64. For the online survey (n = 1,082), the average number of options selected from the SATA was 4.17, and the average number of positive choices in the forced choice grid was 4.72 (a significant difference in means). Respectively, percentages were 6.5% and 7.4%, a difference of 0.9%.
The online survey content and target population of Smyth et al. (2006) and Smyth et al. (2008) were similar to Rasinski et al. (1994), as was the magnitude of the overall difference, suggesting statistically but not practically significant differences.
NatCen Social Research Omnibus Survey
As part of a survey conducted in 2014 by NatCen Social Research, Nicolaas et al. (2015) replicated and extended the Smyth et al. (2008) research to include computer-assisted face-to-face data collection in addition to online and telephone data collection.
Because face-to-face data collection can mimic SATA using showcards, Nicolaas combined their comparison of SATA with forced choice over online and face-to-face sessions.
A key difference in the Nicolaas et al. online study was the use of a series of yes/no questions rather than the yes/no grid used by Smyth et al. (2008).
Across 16 choices (with n varying from 452 to 474 due to some item nonresponse), the average difference in percentages between forced choice and SATA selections was 24%, markedly greater from the percentages reported in the Rasinski et al. (1994) or the Smyth et al. (2006, 2008) studies.
Given the methodological differences, this could be due to the combination of online with face-to-face data or the use of a series of yes/no questions rather than a yes/no grid.
Pew Research American Trends Panel
In 2018, Pew Research used its American Trends Panel to investigate selection rates for SATA and forced choice versions of 12 items (Lau & Kennedy, 2019). Respondents were U.S. adults (n = 4,581) who answered whether they or someone in their family had experienced different undesirable events (e.g., home break-in or denied health insurance). Their method clearly specified that the forced choice format was a series of yes/no questions (not a grid).
They reported the selection rates for each item and format, shown in Table 1. The overall mean difference between the percentage of selections in the SATA condition and the percentage of affirmative responses in the yes/no series condition was 7.3% (95% confidence interval at the item level from 4.6% to 10.0%).
An alternative to comparing percentage selection is to assess differences in the rank order of items (Callegaro et al., 2014). The rank order was similar for the two formats, with a mean absolute rank difference of 0.6 (for percentage data at the item level the Pearson and Spearman correlations were .98 for the two formats).
Item | SATA % | Yes/No % | Difference | SATA Rank | Yes/No Rank | |Rank Diff| |
|---|---|---|---|---|---|---|
1 | 36% | 52% | 16% | 2.5 | 2 | 0.5 |
2 | 22% | 27% | 5% | 6 | 7 | 1 |
3 | 18% | 22% | 4% | 7.5 | 8 | 0.5 |
4 | 16% | 21% | 5% | 9.5 | 9 | 0.5 |
5 | 13% | 19% | 6% | 11 | 11 | 0 |
6 | 4% | 6% | 2% | 12 | 12 | 0 |
7 | 51% | 63% | 12% | 1 | 1 | 0 |
8 | 36% | 45% | 9% | 2.5 | 3 | 0.5 |
9 | 27% | 37% | 10% | 5 | 4 | 1 |
10 | 28% | 32% | 4% | 4 | 5 | 1 |
11 | 18% | 29% | 11% | 7.5 | 6 | 1.5 |
12 | 16% | 20% | 4% | 9.5 | 10 | 0.5 |
Mean | 24% | 31% | 7.3% | 6.5 | 6.5 | 0.6 |
Table 1: Results from Lau & Kennedy (2019).
Table notes: Item is the item number from Lau and Kennedy (2019); SATA % is the overall percentage of selection from the SATA grid; Yes/No % is the overall percentage of affirmative selection from the yes/no series; Difference is Yes/No % minus SATA %; SATA Rank is the rank assigned to the tabled SATA %; Yes/No Rank is the rank assigned to the tabled Yes/No %; |Rank Diff| is the absolute value of the difference in the ranks.
Summary of Previous Research
Consistent with the hypothesis of Sudman and Bradburn (1982), these four lines of empirical research found statistically significant differences in selection rates from SATA and forced choice formats. In all four cases, respondents selected more items for forced choice formats than for the SATA format.
The research, however, differs in the estimated magnitudes of the difference, as shown in Table 2. The range is from less than 1% to 24%.
| Study | Difference |
|---|---|
| Rasinski et al. (1994) | 1.6% |
| Smyth et al. (2006) | 0.8% |
| Smyth et al. (2008) | 0.9% |
| Nicolaas et al. (2015) | 24.0% |
| Lau & Kennedy/PEW (2019) | 7.3% |
Table 2: Estimated magnitudes of SATA and yes/no forced choice differences from previous research.
You could argue that differences of 1–2% would rarely be of practical significance, but that’s a more difficult argument to make for differences of 24% or even 7.3%.
So, why might the results of Nicolaas et al. and Lau and Kennedy be so different from Rasinski et al. and Smyth et al.?
One possibility is the difference in the forced choice format. The literature we reviewed has been inconsistent in two ways:
- Some researchers (Rasinski et al., 1994; Smyth et al., 2006) did not specify whether they used a forced choice grid as originally depicted by Sudman and Bradburn (1982) or a series of yes/no questions.
- Some researchers documented the use of forced choice grids (Smyth et al., 2008), while others documented the use of forced choice series (Nicolaas et al., 2015; Lau & Kennedy, 2019).
Although we cannot tell for sure from the published literature, it seems more likely than not that Rasinski et al. (1994) and Smyth et al. (2006) used forced choice grids. This is plausible because
- Bradburn was an author on the Rasinski et al. (1994) paper, and Sudman and Bradburn (1982, pp. 165–168), discussing two formats for having people select multiple choices from a list, illustrated in their Figure 43 a SATA (Format A) and a forced choice grid (Format B).
- We know from the description of the method in Smyth et al. (2008), which was a continuation of the research presented in Smyth et al. (2006), that they used a forced choice grid, and they did not say anything about that being a change from their 2006 research method.
- Furthermore, Smyth et al. (2006) explicitly stated, “our purpose in this research is to extend the work of Rasinski, Mingay, and Bradburn (1994),” in which case they should either have replicated the Rasinski et al. method or documented the differences.
The main takeaway from the previous research summarized here is that a previously unexamined variable, forced choice grids versus a forced choice series, might account for differences in how closely selection frequencies match when collected with SATA and yes/no forced choice items.
We did not turn up any previous research that directly compared selection rates for forced choice grids versus a forced choice series, so, as usual, we conducted our own study. We’ll report those results in a future article.
Note: This article was adapted from Lewis, J. R., & Sauro, J. (2021). Comparison of Select-All-That-Apply items with yes/no forced choice items. Journal of Usability Studies, 17(1), 21–30.