 The original wording of the UMUX-Lite Perceived Usefulness item is “{Product}’s capabilities meet my requirements.” Since we started using the UMUX-Lite in our practice, we’ve had numerous clients ask whether it would be possible to simplify the wording of this item to more closely match the simplicity of the UMUX-Lite Perceived Ease item, “{Product} is easy to use.” In response to these requests, we’ve investigated the measurement properties of a variety of alternate wordings for this item over the past year.
The original wording of the UMUX-Lite Perceived Usefulness item is “{Product}’s capabilities meet my requirements.” Since we started using the UMUX-Lite in our practice, we’ve had numerous clients ask whether it would be possible to simplify the wording of this item to more closely match the simplicity of the UMUX-Lite Perceived Ease item, “{Product} is easy to use.” In response to these requests, we’ve investigated the measurement properties of a variety of alternate wordings for this item over the past year.
We found very close matches in correspondence of means and response option distributions for three alternates, supporting their use as equivalent items for the original wording:
- {Product}’s functionality meets my needs.
- {Product}’s features meet my needs.
- {Product} does what I need it to do.
For two other alternates, the evidence for equivalency was less clear:
For “functions meet my needs,” the mean difference with “capabilities meet my requirements” was about a quarter of a point on the 0–100-point scale (not a statistically significant difference, n = 212). Analysis of the response options, however, found a statistically significant difference in top-box scores.
The mean difference between “is useful” and “capabilities meet my requirements” was larger (about 1.4 points, n = 201) but also not significantly different. There was no significant difference in top-box scores, but the difference in top-two box scores was about five points—not statistically significant for that data, but large enough for concern regarding scale equivalence. This nominally larger difference made us wonder whether people are more likely that an interface is useful. That is, something can be useful but not quite meet someone’s requirements or needs.
We’ve been running a lot of comparisons of these types of alternates, and we generally find very small differences, so it’s possible these results were due to chance. Replication is a powerful tool to help weed out unusual findings. To check, we collected more data.
The Study: Comparing Two Alternate Usefulness Items
We included the original and both alternate versions of the Usefulness item as part of a survey on the UX of mass merchant websites we conducted in April and May 2021 using an online U.S.-based panel (n = 462). The survey was programmed in MUIQ® so that the different versions of the items were randomly placed and would not appear next to each other.
Results: Comparison of Means
Figure 1 shows the mean UMUX-Lite scores from the study.

Figure 1: Mean UMUX-Lite scores (with 95% confidence intervals).
There was no significant difference between the Original and Alternate 1 (functions/needs) UMUX-Lite scores (t(461) = 0, p = 1.0). Although their standard deviations were slightly different, their means were the same to over four significant digits. The 95% confidence interval around this difference ranged from −.69 to +.69, with 0 in the center. With a difference of 0 being plausible and any difference larger than seven-tenths of a point being implausible, it’s reasonable to conclude that there is no practical difference in means measured with these versions.
On the other hand, the difference between the Original and Alternate 2 (useful) UMUX-Lite scores was statistically significant (t(461) = 3.7, p < .0001). The magnitude of the mean difference was about the same in this study (1.5) as in the previous one (1.4), but the sample size is more than double. The 95% confidence interval around the difference ranged from .69 to 2.2. Because a difference of 0 is not plausible, but one as large as 2.2 is plausible, we cannot reasonably include this in a list of equivalent alternates.
Results: Comparison of Distribution of Response Options
In addition to using the mean, it’s common in UX research to assess data collected using multipoint scales with top-box scores. When there are five response options, both top-one (percentage of 5s) and top-two (percentage of 4s and 5s) box scores are commonly used.
Figure 2 shows the distributions of response options for the standard and alternate versions of the Usefulness item. The response patterns for the Original and Alternate 1 (functions/needs) were similar, and for each response option and the top-two box score, there was a substantial overlap of 95% confidence intervals. As in the previous study, the distribution for Alternate 2 (useful) was shifted to the right relative to the Original, resulting in a 5.4% increase in the top-box score and a 3.6% increase in the top-two box score.
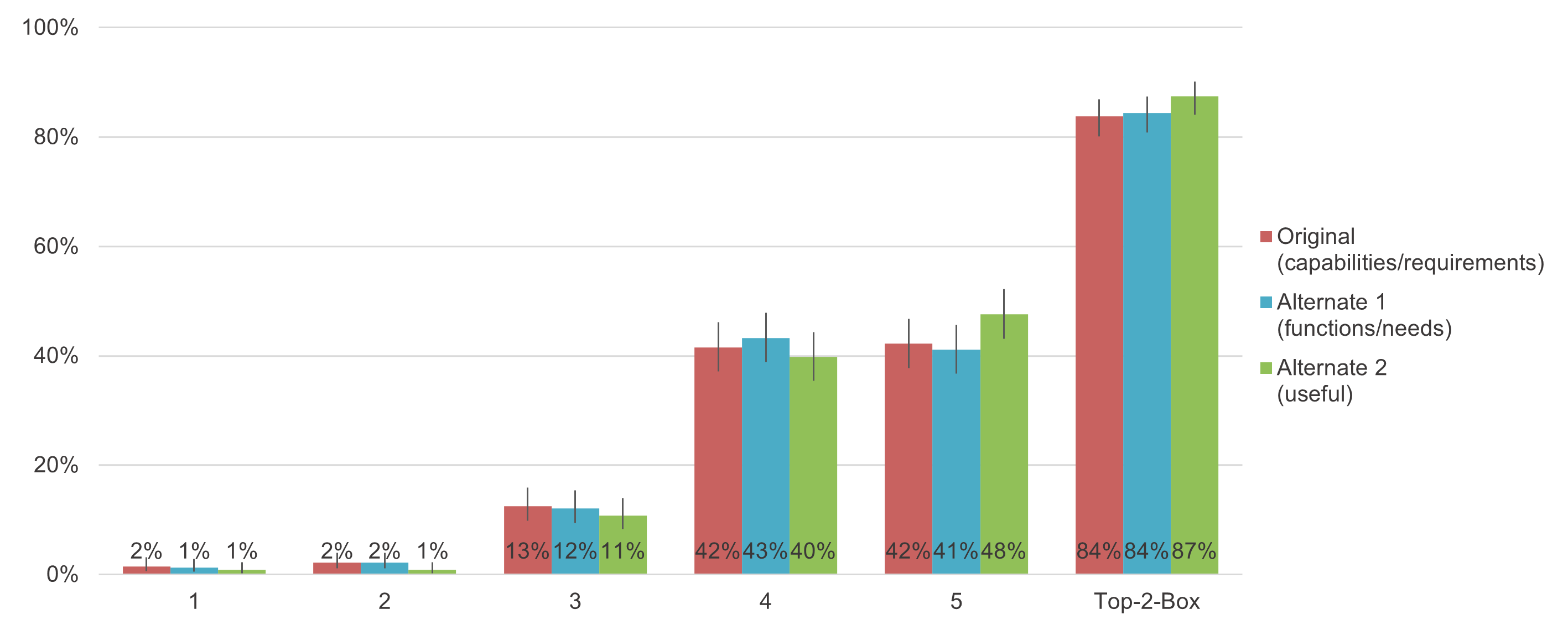
Figure 2: Distributions of Usefulness response options with 95% confidence intervals.
For the comparisons of Original with Alternate 1 (functions/needs), neither the top-box nor top-two box differences were significant. For the top-box scores, the observed difference was 1.1% with a 95% confidence interval around that difference ranging from −2.4% to 4.5% (mid-p = .54). The observed difference for top-2-box scores was 1.0% with a 95% confidence interval around the difference ranging from −2.4% to 3.7% (mid-p = .68).
For both comparisons of Original with Alternate 2 (useful), the scores for Alternate 2 were significantly higher. The top-box scores had an observed difference of 5.4% with a 95% confidence interval ranging from 1.5% to 9.3% (mid-p = .007). The observed difference for top-two box scores was 3.4% with a 95% confidence interval around the difference ranging from .5% to 6.3% (mid-p = .02).
Results: Scale Reliabilities
Scale reliability, measured with coefficient alpha, was .84 for the UMUX-Lite using the Original version of the Usefulness item. For the UMUX-Lite using Alternate 1 (functions/needs), it was .82 and when using Alternate 2 (useful), it was .78. All of these exceed the typical reliability criterion of > .70 for research metrics.
Results: Construct Validity
Given the apparent difference in the distribution of Alternate 2 (useful) scores compared to the Original and our assumption that the various alternates we’ve been studying reflect a latent construct of Usefulness, we conducted a parallel analysis of the three versions collected in the current study. We also measured the correlations among the three versions. All correlations exceeded .90 and were highly significant. The parallel analysis indicated that the three versions were all aligned with the same underlying construct, consistent with our working hypothesis.
Summary and Takeaways
This replication of two UMUX-Lite Usefulness alternates found that Alternate 1 (“functions meet my needs”) produced scores (mean and top-box) that were almost identical to the Original (“capabilities meet my requirements”). Two other alternates (“functionality meets my needs” and “features meet my needs”), investigated earlier, also nearly matched the Original’s scores.
The replication of Alternate 2 (useful) found differences that were similar in magnitude to its earlier assessment, but with the larger sample size in this study, we found those differences (mean and top-box) to be both statistically and practically significant.
Despite the difference in response distributions for Alternate 2 (useful), correlation and parallel analysis demonstrated that all three versions have strong structural connections to the latent construct of perceived usefulness.
This replication adds more evidence to our original thinking: it’s slightly but consistently easier for people to agree that something is useful than to agree that it meets their needs.
Based on these findings and the results from our previous studies, UX practitioners can use any of the following five Usefulness items in UMUX-Lite studies. Practitioners should avoid using “{Product} is useful” due to its relative lack of measurement correspondence.
- {Product}’s capabilities meet my requirements.
- {Product}’s functionality meets my needs.
- {Product}’s features meet my needs.
- {Product}’s functions meet my needs.
- {Product} does what I need it to do.
This does not mean “{Product} is useful” doesn’t have a role in assessing the usefulness of a product or interface; it just means that it’s not an adequate substitute for the original UMUX-Lite item. We’ll continue to investigate usefulness in upcoming research, and we’ll discuss this and other findings in our upcoming webinar on the UX-Lite.


