 The UMUX-Lite is a popular two-item measure of perceived usability that combines perceived ratings of Ease and Usefulness, as shown in Figure 1.
The UMUX-Lite is a popular two-item measure of perceived usability that combines perceived ratings of Ease and Usefulness, as shown in Figure 1.
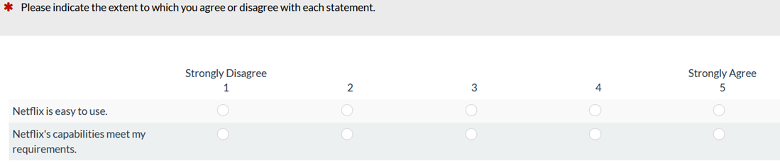
Figure 1: Standard version of the UMUX-Lite (standard item wording with five-point scales).
Since we began regularly using the UMUX-Lite in our practice, we’ve had numerous clients ask whether it would be possible to replace the Usefulness item, citing its relative linguistic complexity. Using Google search to estimate relative word frequencies of the key components of the two items, the words “easy” and “use” have 5.1B and 12.4B hits respectively, while “capabilities” and “requirements” have 0.5B and 5.7B hits. This matters because high-frequency words tend to be more quickly and accurately understood than low-frequency words, making a preference for high-frequency words an important strategy when writing items for surveys or standardized questionnaires.
In response to this desire to simplify the Usefulness item, we’ve investigated several potential alternates. When developing an alternative version of an item for a standardized questionnaire such as the UMUX-Lite, you must conduct research to see if the alternate form behaves like the standard form regarding central tendency (mean) and response distributions (especially, top-box and top-two-box scores).
In this article, we review the research on Usefulness alternates that we conducted over the past year.
Five Alternates to the Usefulness Item
In chronological order, we studied these alternates:
- {Product}’s functionality meets my needs.
- {Product}’s features meet my needs.
- {Product}’s functions meet my needs.
- {Product} does what I need it to do.
- {Product} is useful.
{Product}’s functionality meets my needs
In this alternate, “functionality” (0.5B hits) replaced “capabilities” (0.5B hits) and “needs” (9.8B hits) replaced “requirements” (5.7B hits). Across three independent studies, there were no significant mean differences between the standard and the alternate, with observed mean differences across the studies just fractions of a point (0.1, 0.1, and 0.3) on the UMUX-Lite’s 0–100-point scale. In each study, the patterns of response options for the original and alternate wording were consistent and were not significantly different for each response option (substantial overlap of 95% confidence intervals).
Because the changes from the standard to the alternate wording were small, these results were not surprising. It was, however, important to verify this measurement equivalence before using the alternate in practice.
{Product}’s features meet my needs
In addition to replacing “requirements” (5.7B hits) with “needs” (9.8B hits), we replaced “capabilities” (0.5B hits) with “features” (6.4B hits) in a survey of the UX of auto insurance companies (n = 332). The mean difference was −.45 with a 95% confidence interval ranging from −1.28 to .37. Because the interval contained 0, the difference was not statistically significant, and because the largest plausible difference was just over one point on the 0–100-point scale, the true difference is not likely to be practically significant. The patterns of response options were almost identical, with no difference exceeding 1.8%.
The changes in this alternate were greater than “functionality meets my needs” (.45 vs. a max mean difference of .3 points), but the outcome was the same—no significant differences in means or response option distributions.
{Product}’s functions meet my needs
The structure of this alternate was very close to the previous one, replacing “features” (6.4B hits) with “functions” (2.8B hits), which has fewer Google hits than “features” (6.4B hits) but over five times as many as “capabilities” (0.5B). We collected data with the original and alternate forms in a survey of the UX of food delivery services (n = 212).
In that study, the mean difference was about a quarter of a point (not a statistically significant difference, with a 95% confidence interval ranging from −1.22 to .75). Analysis of the response options, however, found a statistically significant difference in top-box scores.
This result was surprising because this alternate was so similar in form to the previous one, so we replicated that comparison in another survey (UX of mass merchant websites) with a larger sample size (n = 462). In that replication, there was no statistical or practical difference in the means or response distributions between the original (capabilities/requirements) and the alternate (functions/needs), supporting the addition of this item to the set of validated alternates (and reinforcing the importance of replication).
{Product} does what I need it to do
Although this alternate has a different sentence structure from the previous “X meets my Y” alternates, it has a similar meaning. It’s completely made up of high-frequency words (e.g., 9.9B hits for “need”; 22.8B hits for “does”). We included it, along with the standard version, in a survey of two types of online sellers—mass merchants such as Amazon, Walmart, and Target and seller marketplaces such as eBay (n = 260). We set up the survey as a Greco-Latin experimental design so we could focus on within-subjects comparisons of the standard and alternate versions of the UMUX-Lite.
The mean difference between the standard and alternate versions of the UMUX-Lite was .72 (a nonsignificant difference less than 1% of the maximum possible difference of 100), with a 95% confidence interval ranging from −2.0 to 3.4. The distributions of response options were similar for the two versions of the Usefulness item, with no statistically or practically significant differences in top-box scores.
Despite its different sentence structure and simplified wording, the measurement properties of this alternate closely matched the standard version.
{Product} is useful
Borrowing from the terminology of the Technology Acceptance Model (TAM), and supported by recent structural analyses of the relationships among the TAM, UMUX-Lite, likelihood to recommend, and overall experience, we refer to the two items of the UMUX-Lite as Perceived Ease-of-Use and Perceived Usefulness (Ease and Usefulness for short). This led us to test a direct wording of the Usefulness item, “{Product} is useful.” There were 1.5B hits for “useful,” which is fewer than we’d expected but still about three times more than “capabilities” or “functionality.” We included it in a survey of two types of online sellers using a Greco-Latin experimental design (similar to the evaluation of the “does what I need it to do” alternate, n = 201).
Although it was not statistically significant, the mean difference of 1.4 points (95% confidence interval from −1.7 to 4.6) was larger than we’d seen with the other alternates. There also were no significant differences in top-box scores, but the difference in top-two-box scores was about five points—not statistically significant for that data, but large enough for concern regarding scale equivalence.
To double-check, we replicated that comparison in another survey (UX of mass merchant websites) with a larger sample size (n = 462). The difference between the standard and alternate UMUX-Lite scores was statistically significant (t(461) = 3.7, p < .0001). The magnitude of the mean difference was 1.5 (ratings of “useful” higher than those of “capabilities meet my requirements”), which was very close to the mean of 1.4 from the first evaluation (but the sample size in this replication was over twice as large). The 95% confidence interval around the difference ranged from .69 to 2.2. Analysis of top-box scores also had statistically significant outcomes with higher percentages for “useful” (a 5.4% increase in the top-box score and a 3.6% increase in the top-two-box score).
These differences were not only statistically significant, but for the purpose of establishing measurement equivalence, they were also practically significant—potentially large enough that we cannot recommend this wording as an alternate for the Usefulness item.
But if we are trying to measure usefulness, why don’t we recommend using the word useful? To investigate whether the UMUX-Lite item measures the latent construct of Usefulness, we conducted a parallel analysis of the three versions collected in the mass merchant UX study and measured the correlations among the three versions that we concurrently collected in the replication study—“capabilities meet my requirements,” “functions meet my needs,” and “is useful.”
The three correlations were highly significant (all r > .90) and the parallel analysis indicated that the three versions aligned with the same underlying construct. Based on these new analyses and other recent structural research, it’s reasonable that this latent construct is indeed Usefulness.
Our interpretation of the difference between the other alternates and “{Product} is useful” is that it’s slightly but consistently easier for respondents to agree that something is useful than to agree that it meets one’s needs. That means participants will tend to rate experiences on average even higher than the generally already high ratings we’ve seen from several years of UMUX-Lite studies (lots of 4s and 5s). So using items that are slightly less easy to agree to should help some with discriminating between merely good and excellent experiences and will allow us to use the data we’ve already collected to develop UMUX-Lite norms.
Finally, this finding doesn’t mean you should never use the “useful” item to measure the perceived usefulness of an interface. It just means this alternate is not an adequate substitute for the originally validated Usefulness item in the UMUX-Lite because participants tend to more strongly agree with it than with the original.
Key Takeaways
Based on these findings, UX practitioners can use any of the following five Usefulness items in UMUX-Lite studies.
- {Product}’s capabilities meet my requirements.
- {Product}’s functionality meets my needs.
- {Product}’s features meet my needs.
- {Product}’s functions meet my needs.
- {Product} does what I need it to do.
Despite its clear connection to the construct of Usefulness, practitioners should avoid using “{Product} is useful” as an alternate to the original “capabilities” item due to its relative lack of measurement correspondence with the standard version. It doesn’t mean you can’t or shouldn’t use this item in general to measure the perception of an experience. It just means it’s not an adequate substitute for replacing the originally validated item in the UMUX-Lite.