 The completion rate jumped from 20% to 80%. That’s a large effect size. If it had gone from 20% to 21%? Much smaller effect.
The completion rate jumped from 20% to 80%. That’s a large effect size. If it had gone from 20% to 21%? Much smaller effect.
It’s easy to get caught up in the mechanics of significance testing and p-values. But even before those tools existed, researchers were measuring effect sizes. Effect sizes remain fundamental to understanding whether a result actually matters.
An important outcome of recent debates about significance testing has been increased consensus on reporting effect sizes alongside p-values.
It’s been a bit trendy lately to trash null hypothesis significance testing (NHST) because of how it’s misused. Many critics argue we should abandon it altogether.
But if you know us, you know we think that just because something is misused (like the NPS) doesn’t mean we should throw it out. We’re pragmatic. We actually agree with the critics of significance testing that we shouldn’t rely on just p-values. Effect sizes and confidence intervals should be used more to understand the practical significance of a result.
We’ve written about this earlier. Figure 1 shows a framework we originally published in 2021 that extends the all-or-none decision of statistical significance to considerations of practical significance based on confidence intervals (a type of effect size).
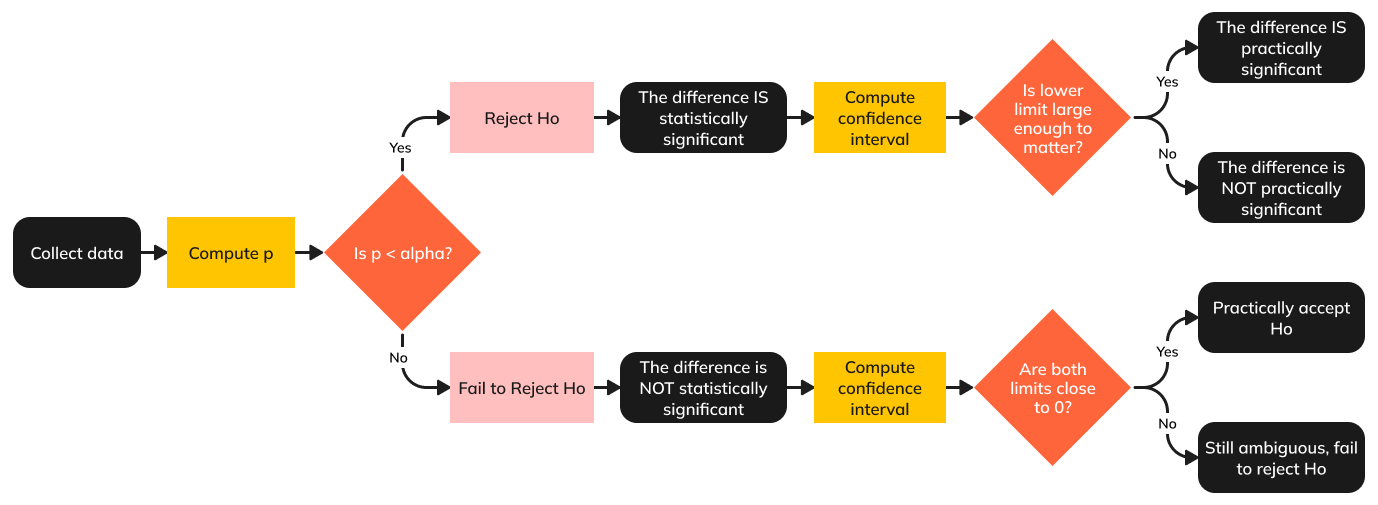
Figure 1: Decision tree for assessing statistical and practical significance.
In this article, we provide a short introduction to effect sizes, extending our thoughts from our earlier article.
A Short History of Effect Sizes
Before there were tests of significance, there were effect sizes. Any time two values are compared, you have an estimate of an effect size.
A key difference: the magnitude of a p-value is affected by sample size, but estimates of effect sizes are not. Significance testing separates effect sizes that could plausibly be zero from those that cannot (typically using an alpha criterion), but the effect size itself is independent of sample size.
Early concepts related to effect sizes can be found in the writings of Francis Galton and Karl Pearson on correlation and regression in the late 19th and early 20th centuries. In 1960, Ronald Fisher added a general statement about the importance of effect sizes to the 7th edition of The Design of Experiments, saying researchers should never “lose sight of the exact strength which the evidence has in fact reached” (p. 25).
Interest in effect sizes grew in the second half of the 20th century with Jacob Cohen’s use of the smallest important effect size to detect (i.e., the critical difference) in sample size estimation and the development of meta-analysis by Gene Glass and Larry Hedges.
In 1994, the American Psychological Association (APA) first explicitly recommended reporting effect sizes in the 4th edition of its publication manual. In the 5th through 7th editions (2019), they strongly recommend reporting confidence intervals around effect size estimates in addition to standard tests of significance.
Types of Effect Sizes
There are many different effect sizes, with estimates of the number varying from 50 to 100. At a high level, they measure either differences (between means or proportions) or relationships (correlations, regression) and can also be classified as unstandardized or standardized. More formally, effect sizes reflect the magnitude of a phenomenon and can be described in terms of what is measured (differences or relationships), how it is computed, and the resulting value.
Because any effect size estimate will be wrong to some degree, the current best practice is to report confidence intervals alongside effect sizes. Confidence intervals show the plausible range of values for an effect size, helping distinguish between statistical significance and practical importance.
Unstandardized Effect Sizes
Unstandardized effect sizes preserve the original measurement units—inches, seconds, or points on a rating scale. Because they’re directly interpretable, they’re usually easier to understand and apply. Common examples in UX research: mean differences and regression coefficients (B weights).
Standardized Effect Sizes
Standardized effect sizes are, for the most part, unstandardized effect sizes divided by a standard deviation. This converts original units into unit-free measures of magnitude, making them easier to compare across studies or combine in meta-analysis. The best-known standardized effect size for the difference between two independent means is Cohen’s d (the mean difference divided by the pooled standard deviation). In UX research, the correlation coefficient is probably the most common standardized effect, possibly because it is more easily interpreted than its unstandardized counterpart, the covariance.
Interpreting Standardized Effect Sizes
The best-known guidelines for interpreting standardized effect sizes as small, medium, or large were developed by Jacob Cohen. He emphasized the importance of basing effect size comparisons whenever possible on the results of previous studies in the relevant research context, but he provided general conventions to use when relevant research was insufficient (Table 1).
Interpretation| Mean Difference | Correlation | Cohen’s Basis
| |
|---|---|---|---|
| Small | 0.2 | 0.1 | Noticeably smaller than medium but not trivial |
| Medium | 0.5 | 0.3 | Visible to naked eye in real world (e.g., height) |
| Large | 0.8 | 0.5 | Same distance above medium as small is below |
Table 1: Cohen’s conventions for interpreting standardized mean differences (standard deviation units) and correlations.
Are Cohen’s Guidelines Applicable to UX Research?
Research on the meaningfulness of effect sizes in psychological research has found larger reported effect sizes for conventionally published research (potentially affected by publication bias) compared to pre-registered research, and differences within subdisciplines of psychology. Another line of research, evaluating effect sizes in psychological research and focused on correlation, recommended interpreting reliably estimated correlations of .05 as very small, .10 as small, .20 as medium, .30 as large, and .40 as very large.
Although quantitative methods in UX are largely borrowed from psychology, UX research differs in goals, constraints, and decision contexts—making direct adoption of interpretation guidelines problematic. We’re planning to analyze our historical research (unaffected by publication bias) to develop guidelines specific to UX research contexts.
Summary and Discussion
In this article, we provided a brief history of effect sizes, two basic types (differences, relationships), and guidelines for interpretation.
Effect sizes predate significance testing. Early concepts appeared in the late 19th and early 20th centuries and were further developed for sample size estimation, power analysis, and meta-analysis in the second half of the 20th century. Major organizations now strongly recommend reporting them.
Effect sizes can be unstandardized or standardized. Unstandardized effect sizes preserve original measurement units; standardized effect sizes (unit-free measures based on proportions of standard deviations) enable cross-study comparison. Other types of research, including sample size estimation and meta-analysis, require standardized effect sizes.
Effect sizes measure differences or relationships. Standardized effect sizes for mean differences include Cohen’s d and Hedge’s g. Standardized effect sizes for relationships include correlations (r) and coefficients of determination (R²).
Report confidence intervals with effect sizes. Any point estimate will be wrong to some degree. Confidence intervals show the plausible range around a point estimate.
Interpretation guidelines are context-dependent. Cohen’s conventions provide a starting point, but research has found larger effects in conventionally published research than in pre-registered research (potentially due to publication bias) and variation across psychological subdisciplines. We plan to investigate effect sizes in our historical data to develop better guidelines for UX research.
We will discuss specific effect size formulas and calculations in future articles.
Additional Reading
Cohen, J. (1962). The statistical power of abnormal-social psychological research: A review. Journal of Abnormal and Social Psychology, 63(3), 145–153.
Cohen, J. (1990). Things I have learned (so far). American Psychologist, 45(12), 1304–1312.
Ferguson, C. J. (2009). An effect size primer: A guide for clinicians and researchers. Professional Psychology: Research and Practice, 40(5), 532–538.
Fisher, R. A. (1971). The design of experiments (9th ed.). Hafner.
Fritz, C. O., Morris, P. E., & Richler, J. J. (2012). Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology: General, 141(1), 2–18.
Funder, D. C., & Ozer, D. J. (2019). Evaluating effect size in psychological research: Sense and nonsense. Advances in Methods and Practices in Psychological Science, 2(2), 156–168.
Galton, F. (1889). Natural inheritance. Macmillan.
Huberty, C. J. (2002). A history of effect size indices. Educational and Psychological Measurement, 62, 227–240.
Kelley, K., & Preacher, K. J. (2012). On effect size. Psychological Methods, 17(2), 137–152.
Levin, J. R. (1998). What if there were no more bickering about statistical significance tests? Research in the Schools, 5(2), 43–53.
Lewis, J. R., & Sauro, J. (2021, June 15). From statistical to practical significance. MeasuringU.
Lewis, J. R., & Sauro, J. (2021, September 28). For statistical significance, must p be < .05? MeasuringU.
Onwuegbuzie, A. J., Levin, J. R., & Leech, N. L. (2003). Do effect-size measures measure up? A brief assessment. Learning Disabilities: A Contemporary Journal, 1(1), 37–40.
Rosnow, R. L., & Rosenthal, R. (1989). Statistical procedures and the justification of knowledge in psychological science. American Psychologist, 44(10), 1276–1284.
Sauro, J. (2014, March 11). Understanding effect sizes in user research. MeasuringU.
Schäfer, T., & Schwarz, M. A. (2019). The meaningfulness of effect sizes in psychological research: Differences between sub-disciplines and the impact of potential biases. Frontiers in Psychology: Quantitative Psychology and Measurement, 10, Article ID: 813.