 We write extensively about standardized UX metrics such as the SUS, PSSUQ, and SUPR-Q. The main benefits of standardization include improved reliability, validity, sensitivity, objectivity, quantification, economy, communication, and norms.
We write extensively about standardized UX metrics such as the SUS, PSSUQ, and SUPR-Q. The main benefits of standardization include improved reliability, validity, sensitivity, objectivity, quantification, economy, communication, and norms.
Even when standardized UX questionnaires are developed independently, they are influenced by earlier work, just like how UX itself is a new field built upon earlier fields.
The deep roots of questionnaire development date back over 100 years. Using an evolutionary analogy, we can place UX questionnaires on three branches, starting in the 1970s.
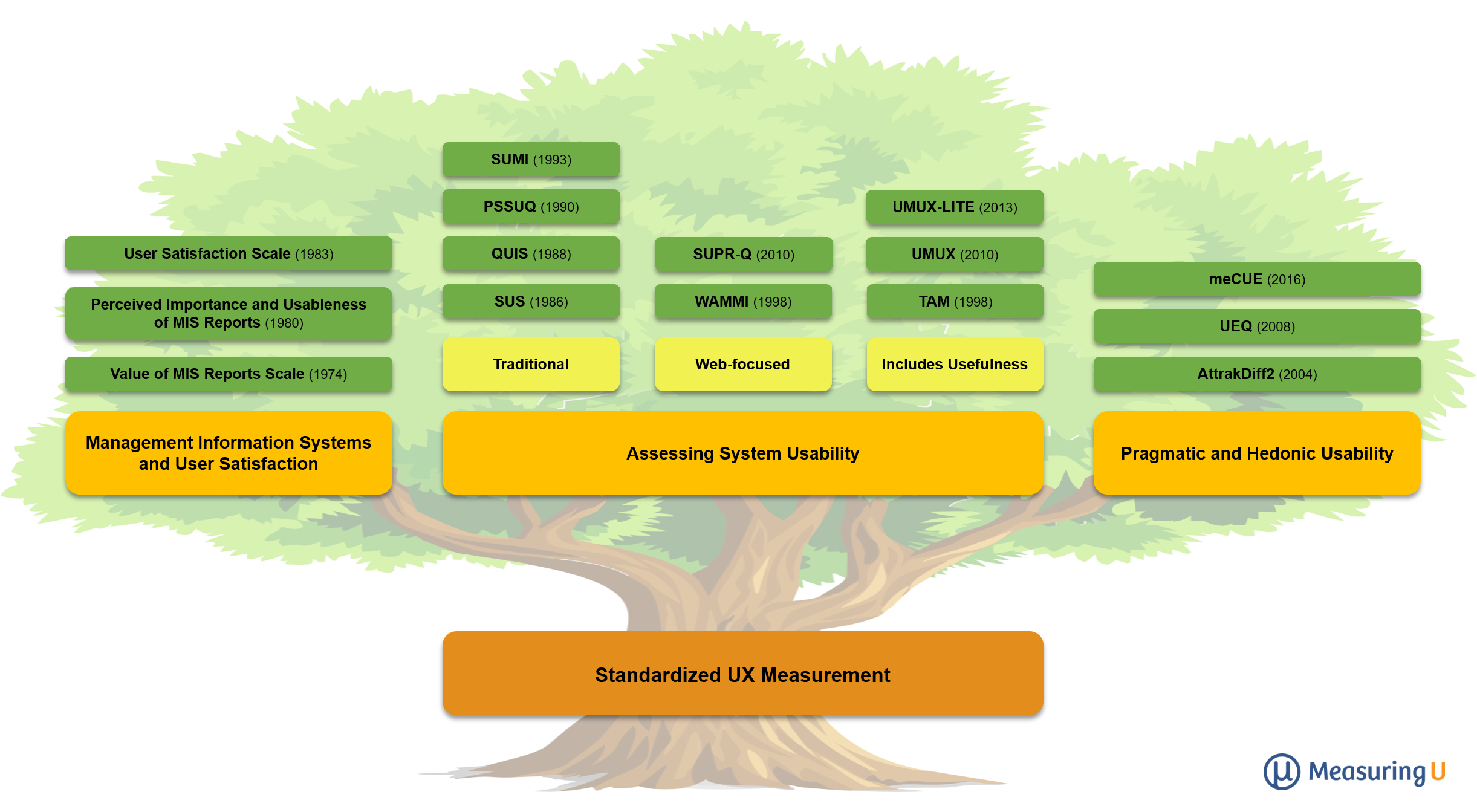
First Branch: Management Information Systems and User Satisfaction
Since the mid-1970s, there have been several branches of development for standardized questionnaires that, in retrospect, have connections to the modern concept of User Experience (UX). For example, in a survey of user satisfaction scales published in 1990, LaLomia and Sidowski described the first branch that included three scales:
- Gallagher’s (1974) “Value of MIS Reports Scale”: Made up of 15 bipolar semantic differentials designed to address quantity, quality format, quality reliability, timeliness, and cost of computer-generated Management Information Systems (MIS) reports.
- Larcker and Lessig’s (1980) “Perceived Importance and Usableness of MIS Reports”: Made up of six rating scales designed to measure perceived importance and perceived usableness.
- Pearson and Bailey’s (1983) “User Satisfaction Scale”: Made up of 39 items to cover system characteristics such as accuracy, error recovery, attitude of support staff, documentation, and data security.
Other than the Pearson and Bailey user satisfaction scale, the first branch suffers from serious limitations in psychometric qualification. The first two were narrowly focused on MIS reports, and all three were created for the assessment of employee judgments of mainframe computers used in their workplace. None of them is suitable for use in scenario-based usability tests.
Second Branch: Assessing System Usability
The second branch started in the late 1980s when, along with the emergence of personal computers and consumer software, there was an uptick in hiring human-factors engineers and experimental psychologists in the computer industry. The questionnaires in this branch were primarily intended for assessing subjective elements in usability testing, and included:
- SUS (1986): The System Usability Scale was developed at DEC in the UK. This ten-item questionnaire, published in 1996, is the most widely used standardized measure of perceived usability.
- QUIS (1988): Developed at the Human-Computer Interaction Lab at the University of Maryland, the Questionnaire for User Interaction Satisfaction is available in short and long versions (26 and 71 items). Respondents use bipolar semantic differentials to rate overall reaction and up to 11 specific interface factors.
- PSSUQ (1990): The Post-Study System Usability Questionnaire was developed at IBM. The current version has 16 agreement items and produces four measures: Overall, System Usefulness, Information Quality, and Interface Quality.
- SUMI (1993): The Software Usability Measurement Inventory has six subscales (global, efficiency, affect, helpfulness, control, and learnability) computed from the responses to 50 items.
- TAM (1998): The Technology Assessment Model, although originally developed to predict the likelihood of future use rather than user experience, can be slightly modified for use as a standardized UX questionnaire (e.g., Lewis, 2019). This modification retains the famous factor structure of the TAM such that it measures both perceived ease-of-use and perceived usefulness.
- WAMMI (1998): Based on the factor structure of SUMI, the Website Analysis and Measurement Inventory has the same six subscales computed from the responses to 60 rating items. The WAMMI was the first standardized UX questionnaire to focus on the web experience.
- SUPR-Q (2010): The Standardized User Experience Percentile Rank Questionnaire, similar to the WAMMI, has its focus on the web experience. It is a concise instrument, requiring just eight items to measure four UX attributes: Usability, Trust, Loyalty, and Appearance.
- UMUX (2010): The Usability Metric for User Experience was developed to be a short four-item measure of perceived usability whose scores would match the SUS. Research over the past ten years shows that the UMUX appears to have achieved that goal.
- UMUX-Lite (2013): The UMUX-Lite is an ultrashort two-item questionnaire made up of two items from the UMUX, one addressing perceived usefulness and the other addressing perceived ease-of-use, making it not only a compact measure of perceived usability but also a compact version of the TAM. Like the full UMUX, its scores tend to correspond closely with concurrently collected SUS scores. Originally published with seven-point items, recent research has shown that it works just as well when using five- or eleven-point items.
The second branch has proven to be very successful, producing standardized questionnaires that are widely used in academic and industrial usability research. Even though they were not specifically designed to focus on emotional outcomes of experience, some of their items have emotional content. For example:
- SUS: Item 9 is “I felt confident using the system.”
- QUIS: The Overall Reaction items include ratings of “terrible vs. wonderful,” “frustrating vs. satisfying,” and “dull vs. stimulating.”
- PSSUQ: Emotional items include Item 4 (“I felt comfortable using this system”), Item 13 (“The interface of this system was pleasant”), Item 14 (“I liked using the interface of this system”), and Item 16 (“Overall, I am satisfied with this system”).
- SUMI/WAMMI: The entire Affect subscale is dedicated to emotional consequences of interaction.
- SUPR-Q: The Appearance subscale has one emotional item, “I find the website to be attractive.”
- UMUX: The second item of the UMUX addresses frustration (“Using [this system] is a frustrating experience”).
Third Branch: Distinction between Pragmatic (Classical) and Hedonic (Emotional) Usability
The second branch included questionnaires with roots in the US (QUIS, PSSUQ) and Europe (SUS, SUMI, WAMMI), touching upon but not really focused on emotional consequences of interaction. What appears to be a third branch that more directly addresses emotional consequences has its roots firmly in Europe—specifically, Germany.
Starting in 2000, Marc Hassenzahl and colleagues began to publish research that distinguished between classical usability, which they called pragmatic usability, and hedonic usability, defined by a set of semantic differential items such as “interesting-boring” and “impressive-nondescript.” They demonstrated that both factors contribute to the appeal of a product. Since then, he has continued to conduct influential research in this area, exploring other drivers of perceived usability and developing the AttrakDiff2 questionnaire for the assessment of a variety of aspects of the user experience. Following the fundamental distinction between pragmatic and hedonic usability, other German researchers have produced similar standardized questionnaires: the User Experience Questionnaire (UEQ; Schrepp and colleagues) and the Modular Evaluation of Components of Experience (meCUE; Minge and colleagues).
- AttrakDiff2 (2004): The AttrakDiff2 consists of 28 seven-point semantic differential items (e.g., “confusing-clear” for pragmatic quality; “unusual-ordinary” for hedonic), providing measures of pragmatic quality and two aspects of hedonic quality: Stimulation (novelty, challenge) and Identification (self-expression). A short version (eight items) is also available.
- UEQ (2008): Similar to AttrakDiff2, the UEQ assesses pragmatic and hedonic quality with seven-point semantic differential items, but across its 26 items, it subdivides pragmatic quality into Perspicuity, Efficiency, and Dependability, and hedonic quality into Novelty and Stimulation.
- meCUE (2016): The meCUE is based on Thüring and Mahlke’s Components of User Experience (CUE) model, which was partially influenced by Hassenzahl’s early work. In that model, the components are the perception of non-instrumental (hedonic) product qualities such as aesthetics, status, and commitment; emotions; and perception of instrumental (pragmatic) qualities such as perceived usefulness and perceived usability.
The third-branch questionnaires are not yet well established in UX research or practice outside of Europe despite early translation into English (in the case of meCUE, availability in 17 languages). We anticipate increasing interest in these questionnaires, especially if future research with them includes:
- Development of global UX scores based on component scores, which would be of particular value to UX practitioners.
- Concurrent collection of SUS data to investigate which components have strong or weak correlations with the SUS. Furthermore, component and global scores, if converted to a 0–100 point scale, might correspond closely enough with the SUS to take advantage of its open-source norms.
- Improved modeling of the relationship among components of UX and potential antecedents and consequences in research and business.
Summary
One way to characterize the evolution of standardized UX measurement from the fourth quarter of the 20th century through the first quarter of the 21st century is through identification of three branches: Branch 1 starting in the 1970s, Branch 2 starting in the 1980s, and Branch 3 starting in the 2000s.
The first branch produced questionnaires with relatively weak psychometric qualification and narrow focus. The second branch, which includes the well-known SUS, QUIS, PSSUQ, SUMI, TAM, WAMMI, SUPR-Q, UMUX, and UMUX-LITE, utilized stronger psychometric methods and, except for QUIS and TAM, have norms for the interpretation of their scores. The primary appeal of the third branch (AttrakDiff2, UEQ, and meCUE) is the addition of subscales that measure aspects of hedonic usability in addition to pragmatic usability. This third branch is, however, limited relative to the second in certain ways, including avoidance of specification of global measures, lack of research connecting the new measures to existing measures (e.g., SUS, Likelihood to Recommend), and, with the exception of the UEQ, lack of norms for interpreting scores.