 If users can’t complete a task, not much else matters.
If users can’t complete a task, not much else matters.
Consequently, task completion is one of the fundamental UX measures and one of the most commonly collected metrics, even in small-sample formative studies and studies of low-fidelity prototypes.
Task completion is usually easy to collect, and it’s easy to understand and communicate. It’s typically coded as a binary measure (success or fail) dependent on a participant meeting a predetermined success state.
But determining if a task has been completed successfully depends on the data collection method. In some cases, it’s not feasible to collect actual task-completion data, but all is not lost. First, we’ll review how task success is assessed in moderated and unmoderated studies, and then we’ll provide some guidance on how to approximate it when it can’t be collected.
Task Completion in Moderated Studies
While in-person moderated studies have mostly stopped because of the pandemic, moderated remote studies are still possible. For both in-person and remote moderated studies, task success can usually easily be observed by a facilitator or note taker. For example, success may be observed when a blender is added to a cart on a retail website, when an ad is posted using a Google AdWords account, or when an expense report is properly posted with the correct amounts using an enterprise accounting program.
Task Completion in Unmoderated Studies
Even in unmoderated studies, you may still be able to observe success states from screen recordings (such as in our MUIQ platform). This can get rather time-consuming for large-sample-sized benchmarks, though (we’ve watched A LOT of recordings for some studies!), but it’s at least still feasible to determine whether the success state was achieved.
If you lack screen recordings (or don’t want to rely on them) in your unmoderated study, it’s still possible to derive task completion. The two most common methods for unmoderated studies are:
1. A validation question
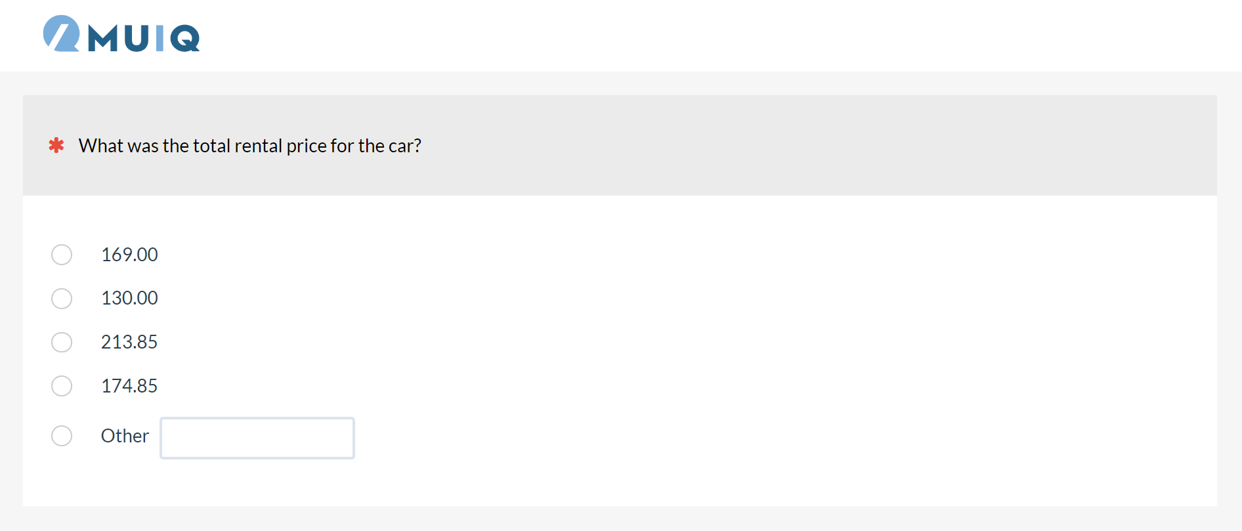
2. URL validation using the location of one or more target URLs

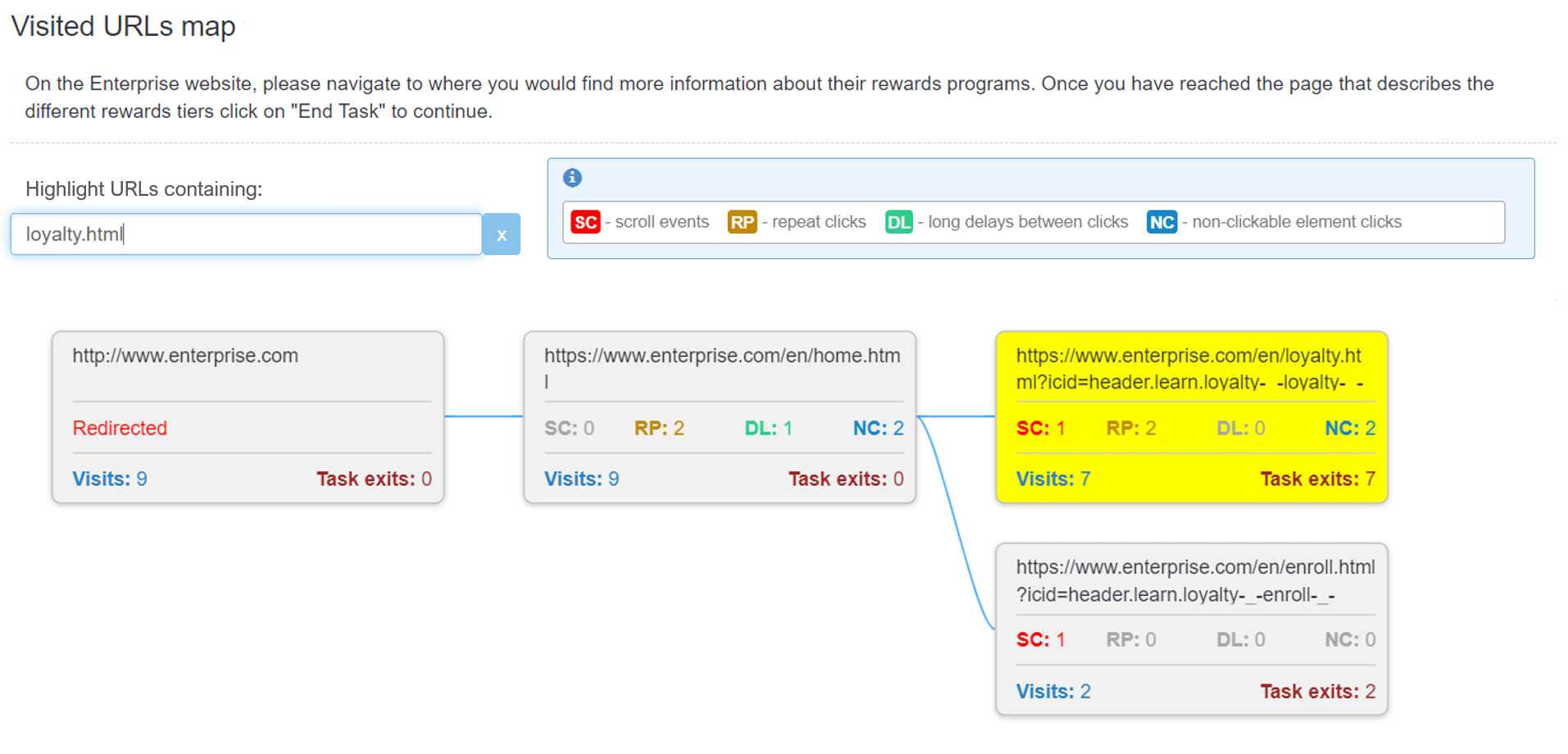
Task Completion in Retrospective Studies
A retrospective study asks participants to recall their most recent experience, after which they answer questions using many of the same metrics as a task-based unmoderated study uses. By definition there are no tasks for these types of studies, so you can’t observe a success state. Instead, you can ask participants about tasks they’ve attempted and have them self-report a completion rate. However, we’ve found that self-reported task-completion rates are almost three times higher than verified completion rates.
The relative rank of products does seem to be reasonably well predicted (if you have conducted a comparative study), but this approach doesn’t seem to be a good proxy for actual completion rates.
Approximating Completion Rates with Perception Metrics
Instead of asking task completion directly, an alternative is to estimate the completion rates from other self-reported metrics at the task and study level using the Single Ease Question (SEQ) and System Usability Scale (SUS) respectively.
Deriving Specific Task Completion with the Single Ease Question
We have found that post-task measurement of ease using the SEQ correlates highly (r = .66) with concurrently collected task-completion rates. The relatively high correlation means we can use the SEQ to predict completion rates with reasonable (although not perfect) accuracy.
For example, a raw SEQ score of 5.1 corresponds to a completion rate of about 68% (with a margin of error around +/- 6%). A raw SEQ score of 6.3 corresponds to a completion rate of 90%. Figure 1 shows this relationship for each SEQ decile, and Figure 2 shows the relationship by SEQ percentile ranks.
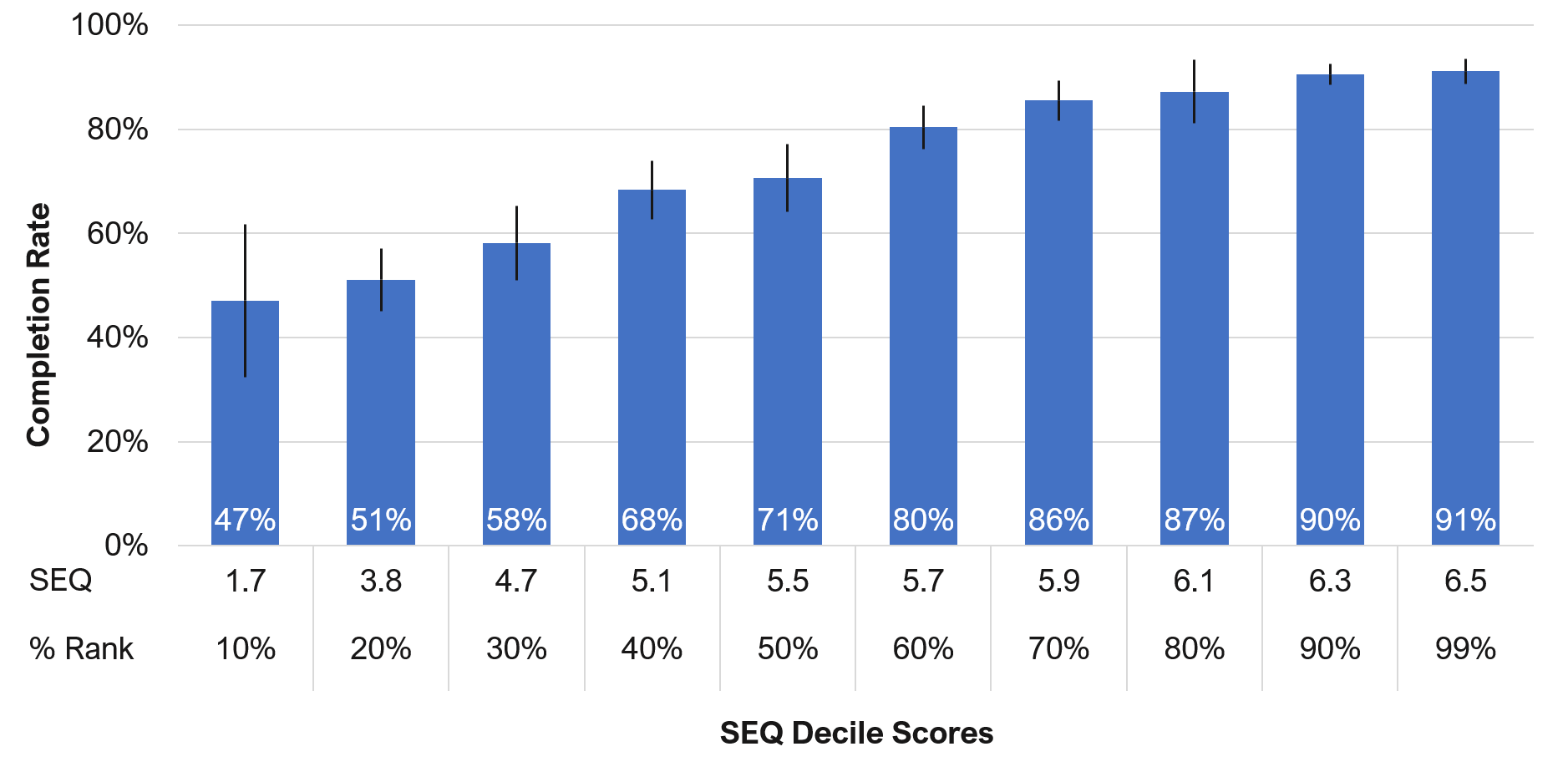
Figure 1: The relationship between SEQ scores (converted into deciles) and completion rates for 286 tasks.

Figure 2: The relationship between SEQ scores (raw and percentile rank) and task completion rates.
To estimate task-completion rates this way, you can provide participants with a task and a specific scenario. For example, thinking about the last time you paid a bill online, how easy or difficult was the task?
The SEQ is not a replacement for task-completion rates, but when it’s difficult or impossible to collect task-completion data, estimating completion rates from SEQ scores can provide an approximation of the completion rate.
Keep in mind that we haven’t verified whether the relationship between the SEQ and completion rates would remain if we weren’t collecting both during a task scenario. We have no a priori reason to believe the relationship would be radically different, but it would be reasonable to examine this in future research.
Deriving Average Task Completion with the System Usability Scale (SUS)
We found a similarly strong relationship with SUS scores and completion rates. SUS is typically collected only once, at the end of a study. Consequently, to have a correlation with task-completion rates, the completion rates need to be averaged together from all tasks.
When aggregated this way, we found a strong correlation between completion rates and SUS decile buckets (r = .9). The reason for the higher correlation is because a lot of variability at the task level is removed when the completion rates are aggregated, thus increasing the correlation. Figure 3 shows the relationship between SUS scores and completion rates.
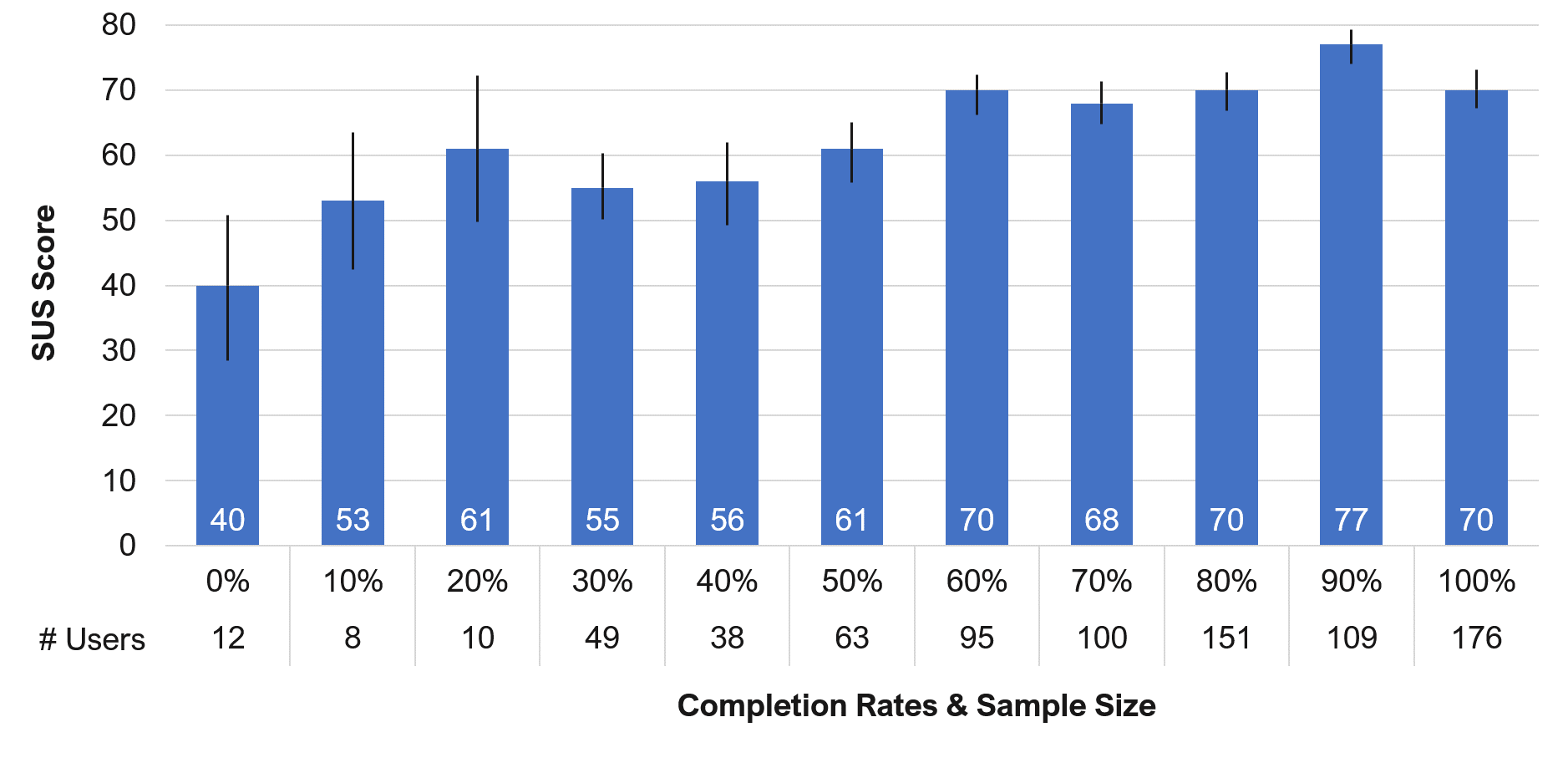
Figure 3: Mean SUS scores for each completion rate “bucket” (0–100%).
For example, SUS scores around 61 correspond with average task-completion rates of about 50%. SUS scores around 70 are associated with average completion rates around 80%. This method isn’t as focused as the SEQ method, because you can judge only average task completion, but it still provides some idea about effectiveness when you don’t have other task-completion data.
Summary
Completion rates are a fundamental usability metric in assessing the effectiveness of an experience. Collecting completion rates is relatively straightforward when you can observe the success state (in moderated and unmoderated studies).
When you can’t observe a success state in an unmoderated task-based study, you can use a post-task verification question or URL tracking. Asking self-reported completion rates (did you complete this task?) tends to result in highly inflated scores. An alternative is to use measures of perceived usability: The post-task SEQ average can approximate individual task-completion rates, and the SUS can approximate the average completion rate across multiple tasks. Future research is needed to see how well the SEQ and SUS predict tasks when they aren’t collected as part of a usability test.