 If you have the budget and time to test with fifteen users, it’s better to break up those fifteen into three groups and make changes between rounds than test all fifteen in one round before making any changes.
If you have the budget and time to test with fifteen users, it’s better to break up those fifteen into three groups and make changes between rounds than test all fifteen in one round before making any changes.
When you see a user struggle to complete a task because of a poorly labeled field or a hidden menu, it can be a waste of time, be painful to watch, block users from encountering other potential issues, and in some cases, be unethical.
But why wait to fix after watching five, four, or three users have the problem? Why not stop after one?
This basic idea of iterative design dates back at least to 1981 when Alphonse Chapanis and his students published research that had an almost immediate influence on product development practices at IBM, Xerox, and Apple. And there is evidence that this approach leads to better experiences.
The emphasis on iterative design differs from experimental design, where the stimuli (interface) should remain the same for all participants to test a hypothesis. But if the goal of the usability test is to find and fix problems and not to compare with a benchmark or product, the iterative approach makes more sense.
In 2002, Medlock et al. described a formative usability testing protocol they called RITE—Rapid Iterative Testing and Evaluation. Here are ten things to know about the RITE method.
- Designs are iterated as quickly as possible. In traditional usability testing, a set number of participants are evaluated before making any changes to the design. That number is usually not large, but it’s usually greater than one. In the RITE method, if a single participant experiences a problem and the usability test team determines that this is a problem they will need to fix, they suspend testing until they have a suitable revision. This doesn’t mean that testing stops after every participant, but after each participant finishes, the usability test team convenes and determines whether to continue without a design change.
- Making rapid changes is not always easy. In principle, it makes sense to fix changes rapidly, but in practice, it can be hard to rapidly fix changes (and not create new bugs or other problems). If it takes more than an hour or two to modify a design, then it will only be possible to test one or two participants per day, which is a much slower rate than traditional formative usability testing (which often runs five in one day). As Medlock et al. (2002) stated, “This means that development time/resources must be set aside to address the issues raised in the test and the development environment is such that rapid changes can be made.” It’s likely that the reason RITE was not described as a method before 2002 was in part due to the difficulty of making rapid design changes with earlier technologies. It may be easier to make changes to prototypes than production code. Medlock and team reference testing with prototypes in their original article.
- RITE existed as a practice well before 2002. Medlock et al. (2002) did not claim to have invented RITE; they were the first to give the method a name to distinguish it from traditional formative usability testing. “The RITE method is not ‘new’—practitioners do this (and other activities like it) all the time. But there is surprisingly little said about methods like it in the literature.” For example, consider this quote from Al-Awar, Chapanis, and Ford (1981, pp. 30–31, 33), written more than 20 years before the 2002 publication of RITE: “Our methodology is strictly empirical. You write a program, test it on the target population, find out what’s wrong with it and revise it. The cycle of test-rewrite is repeated over and over until a satisfactory level of performance is reached. Revisions are based on the performance, that is, the difficulties typical users have in going through the program. … Having collected data from a few test subjects—and initially a few are all you need—you are ready for a revision.”
- It’s unclear when you should stop testing. In RITE, if you see a problem that needs to be fixed, you stop, fix, and resume. But what if you see no problems—when do you stop? This isn’t well defined for RITE. Medlock et al. (2002) reported a case study of the game Age of Empires II in which, after rapid iteration and redesign with ten participants, there were no changes required for the next six participants, so for those six participants, the design did not change—they called this the “verification step.” We can use the same stopping rules in the verification step of RITE testing as we do with typical problem-discovery usability tests. For example, we’ve used the cumulative binomial probability formula to create the following graph, which provides guidance regarding the risk associated with stopping RITE testing after a given number of participants complete tasks without encountering a problem that requires a design change.
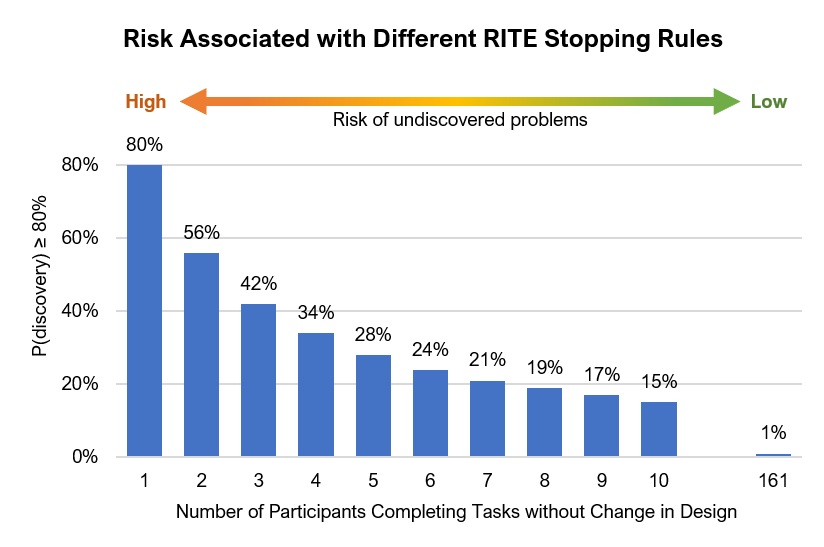
Here’s how the graph works. To simplify the process, we’ve used 80% as a discovery criterion (there’s nothing magic about that decision—we could have used 70%, 90%, or any other reasonable percentage). If you stop testing when n = 1 in the verification step (after one additional user doesn’t have a problem), then you can only claim that you had a good (80%) chance of discovering problems that would happen to 80% or more of the population from which you got your participants. If you stop testing with n = 2 (two users don’t encounter a problem), you can claim that you had a good (80%) chance of discovering problems that would happen to 56% or more of that population. When n = 6, that percentage has dropped to just below 25%; when n = 10, it’s 15%. To get the percentage down to 1%, you’d have to test 161 participants with none of them encountering a problem resulting in a redesign decision. Because small sample discovery methods simply aren’t able to reliably find low probability events, stopping after six change-free participants seems an appropriate balance of risk and expenditure of resources. Stopping after one … not so much.
- RITE proponents claim it’s more effective. According to the chapter on RITE in the second edition of Cost-Justifying Usability (written by some of RITE’s original authors, Medlock, Wixon, McGee, and Welsh, 2005), the advantages of RITE over more traditional usability testing is that RITE results in more issues fixed, more issues found, better team dynamics, and when things go wrong with the special methods of RITE, it degrades gracefully into a standard formative usability test. However, there wasn’t a direct comparison between RITE and traditional usability testing (see #9). What’s more, there’s a risk that unless there is a well-justified stopping rule (see #4), RITE might give an inflated sense of confidence in the problems found and fixed based on the total sample size to stakeholders. For example, if you test with ten users, but changed the interface after users five and eight and found no new issues for users nine and ten, you can’t claim the confidence in problem discovery you’d have with ten users (problems found at the 15%+ level, relatively low risk; see graph in #4), only with two users (problems found at the 56%+ level, relatively high risk). A sample size of ten sounds a lot better than a sample size of two, but in RITE, it’s the sample size in the verification step that matters most.
- Problems are easier to identify than solutions. Potential pitfalls specific to RITE include situations where there is little opportunity for rapid iteration, there is no commitment for the necessary resources, and there are too many decision-makers, which may lead to disagreement. In our experience, while there’s often good agreement from stakeholders that a problem occurred, there’s usually much less agreement on what the change should be in the interface to fix the problem (and not introduce a new one). Compound this with a compressed timeline and the RITE method can sound more like a moving-fast-and-breaking-things method (MFBT).
- A number of companies have tried RITE. In addition to Microsoft, companies that have tried RITE include Nationwide, Oracle, and Citrix. For example, in a case study from Citrix, Shirey et al. (2013) reported a generally positive experience using RITE. They were unable to rapidly address some design problems related to technical product issues and reported needing a large time commitment and deep involvement from the core product team. They concluded that RITE works best when all stakeholders can observe the sessions and engage in face-to-face discussions with participants; for many companies that would require travel expenses. Even though they were set up to do rapid iteration, they ran only six participants and did not report how many ran without the need for additional changes.
- Some researchers have combined RITE with other approaches. Some practitioners have combined RITE with other methods. For example, in 2013, Jen McGinn and Ana Chang described combining RITE with the approach to usability testing promoted by Steve Krug. The goal of this RITE+Krug (KRITE?) method was to meet the challenges of usability testing in agile development. Specific aspects of RITE that they found unsuitable for agile development were the practice of validating fixes (which can take a large number of participants) and the time needed to complete a RITE study due to stopping evaluation while design changes are made. From the Krug approach to usability testing, they abandoned the production of lengthy reports; instead, they conducted daily debriefing sessions with stakeholders and limited documentation to a list of observations.
- There’s been no comparison with traditional formative testing or inspection methods. The arguments in favor of RITE when it’s appropriate seem reasonable, but we did not come across any research that directly compared the effectiveness of RITE with traditional “rapid” formative usability testing or even inspection methods (such as a heuristic evaluation), which may also be as effective at finding the more “obvious” issues the RITE authors describe. For example, with the same fifteen participants described in the Age of Empires II case study, would three rounds of five users have found the same number of or more problems? And would it have been more or less onerous to make changes after five (say at the end of the day) versus every few hours? Conducting a comparison study would be difficult, which is probably why no one has done it yet. Nevertheless, it may be presumptuous (and risky) to assume RITE that would generate a more usable interface than traditional formative testing or an inspection method. The intended goal of RITE is to help in “shipping an improved user interface as rapidly and cheaply as possible.” It may be more rapid to ship, but so far there’s little evidence it’s more effective than traditional formative testing.
- The verification step often is left off. In the original RITE paper, the evaluation didn’t stop until six participants had completed the task without turning up any additional issues serious enough to cause the team to change the design. This RITE verification step takes time but is a critical part of its initial conception. Due to the time required and its location at the end of the RITE process, it appears that few practitioners complete this step. Most of the case studies we found do not even mention continuing to test until a specified number of participants complete the tasks without the need for additional design changes (what you might call RITE-LITE). But without this step, is it really RITE?