
Human: Computer, can you recognize speech?
Computer: I think you said, can you wreck a nice beach?
Both the quality of synthesized speech and the capability of communicating with a computer using your voice have come a long way since the debut of this technology in the 1970s.
One of the most famous synthetic voices was the one used by Stephen Hawking. Some of its peculiarities were due to using one of the oldest approaches, speech synthesis by rule, with a voice created by the speech technology pioneer Dennis Klatt.
When Hawking had the opportunity to switch to a more modern voice in 2006, he stuck with his original voice, saying, “I keep it because I have not heard a voice I like better and because I have identified with it.” Stephen Hawking was a special user of speech technology and, understandably, he preferred to stay with the older technology because it was HIS voice. For most of us, however, disfluencies and irregularities in synthetic speech can be very distracting—and even annoying.
Beyond Hawking, the synthetic voices now used in products have evolved from the distinctly computer-sounding voice used for WOPR in the 1983 movie WarGames to sounding much more like the very human-sounding HAL 9000 in the 1968 movie 2001: A Space Odyssey.
In addition to hearing more realistic synthetic speech, it’s also no longer science fiction to interact with computers using just your voice. HAL has become Siri, Cortana, and Alexa.
But these voice systems aren’t perfect. Just like websites and mobile apps, voice interfaces need to account for the humans with whom they interact. And just like with other interfaces, one of the most effective ways to measure the experience is to use a standardized questionnaire.
We have written about the importance of standardized questionnaire measurement, including the evolution of standardized UX measurement (from the 1970s to the present).
But in addition to general-purpose usability/UX questionnaires, there is a wide variety of more specialized instruments, including three specifically designed to measure either the quality of synthetic speech and/or the experience of interacting by voice. The three questionnaires are
- The Mean Opinion Scale (MOS)
- Subjective Assessment of Speech System Interfaces (SASSI)
- Speech User Interface Service Quality (SUISQ)
1. The Mean Opinion Scale (MOS) and Its Variants
Probably the best-known questionnaire for assessing speech quality is the Mean Opinion Scale (MOS). It was originally developed in the 1980s for the subjective assessment of speech quality over noisy (or otherwise degraded) voice channels (e.g., early cell phone quality).
The MOS has been adopted and adapted for the evaluation of the quality of synthetic speech (aka, text-to-speech, or TTS). It was originally developed in 1994 as a seven-item questionnaire with two factors: Intelligibility and Naturalness. However, later analysis revealed that items didn’t align well to the intended two factors (something we also found in our analysis of the SUS).
To improve the MOS, Polkosky and Lewis (2003) expanded the MOS to 15 items to include measures of prosody (patterns of speech rhythms and melodies) and social impression. The resulting MOS-X questionnaire aligned to the four factors (Intelligibility, Naturalness, Prosody, and Social Impression) and was able to differentiate well among ten synthetic voices.
To further validate the MOS-X, more recently, Jim Lewis had 865 participants listen to dozens of samples of human and synthetic speech made from 2001 to 2017. Participants answered the fifteen-item MOS-X and a four-item questionnaire called MOS-X2, which represented the four factors with one item each (Figure 1). While both questionnaires had good psychometric properties, it turned out the simpler four-item questionnaire did a better job of matching the factors and correlated more strongly (higher concurrent validity) with measures of LTR (likelihood to recommend for use in a service system) and overall quality. Both the range of voice quality and the relatively large dataset also allowed for the creation of benchmarks and a curved grading scale. Not surprisingly, the oldest samples of speech (using technologies from 2001–2002) received consistently poor ratings. We’ll cover more about scoring the MOS-X2 and its history in a future article.

Figure 1: The MOS-X2
2. Subjective Assessment of Speech System Interfaces (SASSI)
In 2000, Hone and Graham published the Subjective Assessment of Speech System Interfaces (SASSI) questionnaire. The SASSI has been used in a number of research papers (at least 200 citations according to Google Scholar). For example, it has been used to measure the usability of such diverse applications as speech-based access to health information, social robots, and conversational agents.
Whereas the MOS-X is specific to measuring speech quality, the SASSI is a broader measure of general speech-system usability. Consequently, the questionnaire is longer and has more subscales. The SASSI has 34 items with six factors: System Response Accuracy (nine items), Likeability (nine items), Cognitive Demand (five items), Annoyance (five items), Habitability (four items), and Speed (two items) (see Figure 2).
To develop the SASSI, Hone and Graham obtained 226 completed questionnaires over the course of four separate studies involving a total of eight different speech input systems. Exploratory factor analysis indicated that the items aligned as expected with the six factors (construct validity), and the reliabilities of the scales developed from each factor were acceptable. Hone and Graham did not, however, provide any data about overall reliability, concurrent validity, or sensitivity. Also, they did not develop any benchmarks for interpreting scores.
Based on their findings (with fairly small sample sizes), Weiss, Wechsung, Naumann, and Möller (2008) reported a probable need to revise the SASSI scales. Hone (2014), one of the originators of the SASSI, has also suggested a need for refinement and to more firmly establish its psychometric properties (also see http://people.brunel.ac.uk/~csstksh/sassi.html).

Figure 2: The SASSI.
3. Speech User Interface Service Quality (SUISQ) and Its Variants
Similar to the SASSI, the SUISQ is a questionnaire designed to assess the usability of Interactive Voice Response (IVR) applications. You’ve likely encountered an IVR if you called customer service and found yourself pressing or saying 1 for Sales, 2 for Support, or 0 to get an operator as fast as you can.
Because IVRs are typically part of an enterprise’s customer service offerings, one of the unique aspects of the SUISQ is its inclusion of items related to satisfactory customer service.
The original SUISQ was made up of 25 items and four factors: User Goal Orientation (UGO: eight items), Customer Service Behaviors (CSB: eight items), Speech Characteristics (SC: five items), and Verbosity (V: four items).
It was developed in 2005 by Melanie Polkosky as part of her doctoral dissertation. It was validated with 862 college students who listened to recordings of users interacting with one of six speech systems (as opposed to actual users rating their experience). This method of rating, by watching others interact, has support in the marketing and interpersonal communication literature (see Cargile, Giles, Ryan, & Bradac, 1994; Dabholkar & Bagozzi, 2002), but its general validity remains an open research question, not something typically done for other UX questionnaires.
Ten years later, Lewis and Hardzinski (2015) conducted a study with 549 employees of a large bank using an unmoderated study. The participants were asked to complete tasks (e.g., change an address, transfer funds, get information about a health savings account, and report a lost debit card). After attempting tasks and self-reporting completion rates, participants answered the SUISQ.
The psychometric properties of reliability, concurrent validity, and construct validity were very similar to those reported by Polkosky (2005), with 23 of 25 items aligning as expected. But Lewis and Hardzinski also found redundancy among the items, which provided an opportunity to reduce the length of a questionnaire.
Lewis and Hardzinski developed (1) a reduced version (14-item SUISQ-R), and (2) a maximally reduced version (9-item SUISQ-MR), which still had desirable psychometric properties (e.g., four-factor structure with reliable scales) but with fewer items. All scales correlated significantly with ratings of satisfaction (concurrent validity) and differentiated on the basis of task completion (sensitivity). Figure 3 shows the 9-item SUISQ-MR that they recommend.
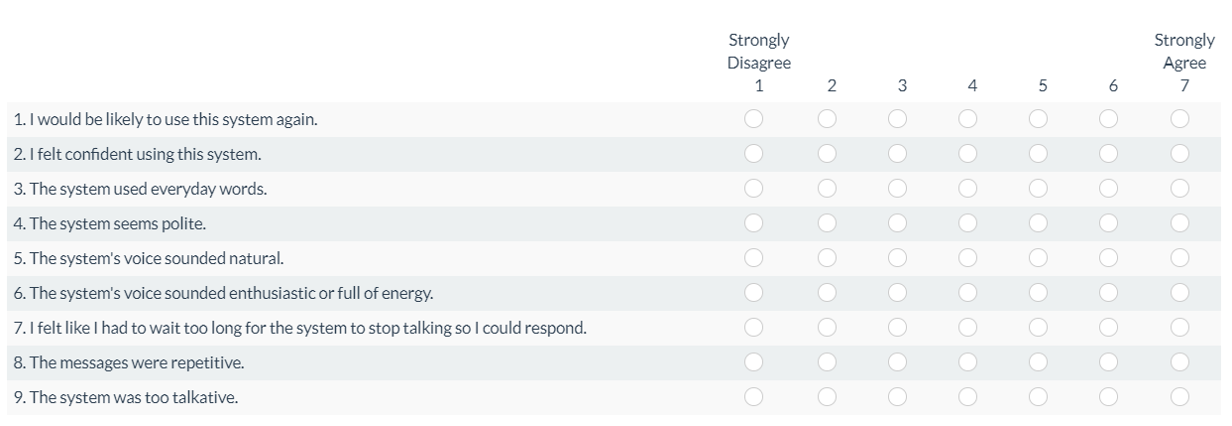
Figure 3: The SUISQ-MR—the four factors are User Goal Orientation (items 1–2), Customer Service Behaviors (items 3–4), Speech Characteristics (items 5–6), and Verbosity (items 7–9)—factor scores are the means of their item ratings; the overall score is the mean of the factor scores after reversing Verbosity using the formula Vr = 8 − V.
Summary and Discussion
Table 1 summarizes the psychometric properties of three standardized questionnaires that measure different aspects of experience with voice user interfaces. There is currently only one version of the SASSI, but several versions of the MOS and SUISQ. Although there may be legitimate reasons to use alternate versions, the preferred versions are the MOS-X2 and SUISQ-MR as described in this article.
| Characteristic | MOS-X2 | SASSI | SUISQ-MR |
|---|---|---|---|
| Designed to assess | Voice quality | General speech system usability | IVR usability |
| Number of Items | 4 | 34 | 25 |
| Number of subscales | 4 | 6 | 4 |
| Overall reliability | 0.85 | NA | 0.80 |
| Subscales (reliabilities) | Intelligibility, Naturalness, Prosody, Social Impression | System Response Accuracy (.90), Likeability (.91), Cognitive Demand (.88), Annoyance (.77), Habitability (.75), Speed (.69) | User Goal Orientation (.88), Customer Service Behavior (.75), Speech Characteristics (.68), Verbosity (.67) |
| Construct validity | Yes | Yes | Yes |
| Concurrent validity | Yes | NA | Yes |
| Evidence of sensitivity | Yes | NA | Yes |
| Availability of norms | Yes | No | No |
Table 1: Summary of Psychometric Properties of the three standardized questionnaires (subscale reliabilities not available for MOS-X2 due to having one item per subscale).
The available data generally support the use of the questionnaires for their intended purposes, but Table 1 shows some gaps in their psychometric qualification. All are multifactor instruments with published subscale reliabilities and evidence of construct validity. There is no published method for computing an overall score for the SASSI, no assessment of its overall reliability, and no published evidence of concurrent validity.
Finally, there are no published norms for the SASSI or any version of the SUISQ. The absence of published norms does not render a questionnaire useless, but the availability of norms dramatically increases its value. Unfortunately, the development of compelling norms for a standardized questionnaire is a relatively difficult effort.
Note: For more in-depth information about the development and use of these questionnaires see Lewis (2016) and Lewis (2018).