 When we conduct a survey, we want the truth, even if we can’t handle it.
When we conduct a survey, we want the truth, even if we can’t handle it.
But standing in the way of our dreams of efficiently collected data revealing the unvarnished truth about customers, prospects, and users are the four horsemen of survey errors.
Even a well-thought-out survey will have to deal with the inevitable challenge these potential errors will pose for the veracity of your data.
While most think that these errors primarily affect surveys (largely because of the ubiquity of this method), they also can affect any research method that involves sampling from a population, including unmoderated UX studies and usability testing.
Adapted from Dillman et al. (2014), here are four errors to watch for and how to handle them when conducting surveys (and other methods that incorporate survey-like questions and sampling).
Unlike the four horsemen of the Apocalypse, these potential errors don’t result in pestilence and war, but they can still wreak mayhem on your results through errors in who answers (coverage, sampling, and non-response) and how people respond (measurement error).
1. Coverage Errors
Representativeness is paramount. Asking the right questions to the wrong people is a recipe for misinterpretation. Coverage errors can range from egregious (surveying general U.S. consumers about European corporate financial compliance) to subtle (surveying only current customers about product satisfaction and not recently churned customers).
The more important it is to draw precise generalizations about a population from a sample, the more important it is to consider the impact of coverage error. While you might not be trying to predict voter turnout in a presidential election to within 1%, other high-stakes decisions may depend on your coverage. Data on intent to purchase, use, or recommend can impact a product’s going to market or affect funding allocations to fix a problem.
For most applied surveys, the question isn’t whether there is coverage error, but how much coverage error there is and what it affects.
The first step in having a survey with good coverage is to increase the chance that everyone in your target population has a chance of responding. This is often referred to as the sample frame. People outside the sample frame have no chance to respond to a survey.
The primary concern with coverage is that the people who answer the survey may differ in some meaningful way from people who, because they’re not in the frame, aren’t invited to participate, resulting in measurements that deviate from the population of interest. This possibility is a primary contributor to the risk in generalizing beyond your sample frame.
Figure 1 shows two depictions of sample frames around the same population, one with less coverage and one with more. The dots outside the squares represent people who aren’t in the frame and therefore won’t be invited to respond. The sample frame may represent a customer list, an online panel, or a database (say, of registered phone numbers).
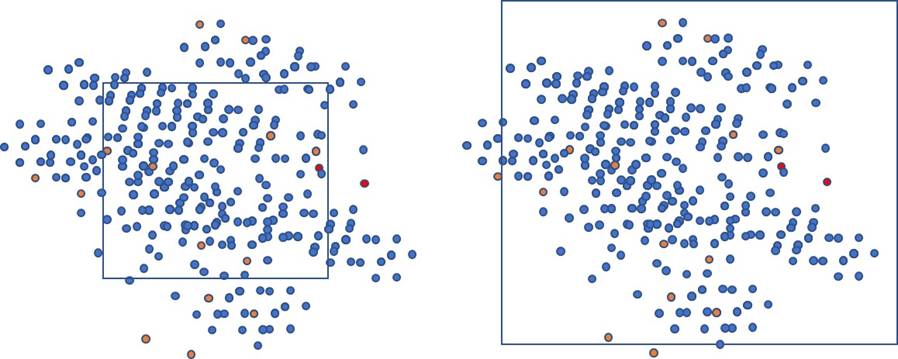
Figure 1: Examples of two sample frames visualized. The sample frame on the left has less coverage than the one on the right; both have the same target population. The non-blue dots represent respondents with distinctly different characteristics than the larger sample (e.g., different purchase intentions or differences in prior experiences).
Before web surveys were possible, a common strategy to get the right sample frame for a representative set of respondents in the U.S. was to use the phone book and call landlines. In the last 20 or so years, the number of people in the U.S. with landlines has dropped considerably. The resulting sample frame shrank, disproportionately excluding certain populations and lessening the coverage and representativeness of this approach for gaining a proportionate sample of the U.S. population (with similar patterns in Europe).
For applied UX research, you’re probably not calling participants and are likely relying on emails sent to online panels of paid participants. Not all panels are created equal. Some panels offer access to probability samples that mirror the broader population of interest on variables such as geography, age, and gender. Most panels, however, collect lists of people and advertise for those to sign up for individual studies—a process that doesn’t necessarily result in a representative population of participants based on proportions of types of users in a specified general population.
Error Reduction Strategy: Include as much of your target population in your sample frame as possible. Consider using probability samples with known sample frames for high-stakes decisions. In UX research, use what you know about your population of interest to define quotas, thus ensuring you collect enough data for each target segment (typically based on experience in certain domains and with specific products).
2. Sampling Error
Unless you have a way of surveying every single person in the population of interest (e.g., all users of a mobile app), you’ll have to deal with sampling error. Sample frames that encompass entire populations of interest are exceedingly rare in applied survey research.
But even if you have a good (or complete) coverage in your sampling frame, you’ll still have to deal with the randomness of sampling error.
Fortunately, sampling error can be estimated rather well. Statistical techniques can tell you how precise your estimates are (confidence intervals) and whether observed differences exceed sampling error (tests of significance, such as t-tests). The more you increase your sample size, the more you reduce the sampling error, the more precise your estimates are, and the better you can differentiate between subgroups.
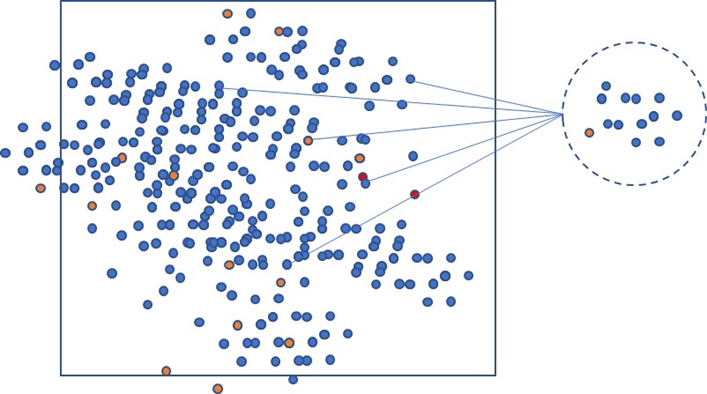
Figure 2: Visualization of a sample taken from the sample frame.
While the math behind confidence intervals seems less intuitive than understanding coverage issues, it’s straightforward to calculate. In contrast, coverage errors are harder to estimate unless you know something about the people who didn’t respond (which we cover next).
Error Reduction Strategy: If your measurements aren’t precise enough for the decisions you need to make, the best way to reduce sampling error is to increase your sample size. There is, however, a diminishing return as you increase your sample size, especially past a few hundred.
3. Non-Response Error
You can have excellent coverage, a great sampling strategy, and even a large sample size, but some people may not respond. They may drop out before answering any questions, answer only the first few questions, or skip non-required questions (see Figure 3).
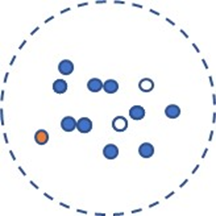
Figure 3: Visualization of respondents in a survey sample who didn’t respond (empty dots).
The response rate is the first place to start when estimating non-response error (i.e., the percent of people who completed compared to those invited). It’s better to have a high response rate (e.g., 85%) than a low response rate (e.g., 5%). However, even a high response rate can’t fully tell you how much non-response error you have. For example, a question asking about income may cause many high- or low-income respondents to abandon the survey.
Similar to coverage error, the major concern for non-response error is that the people who answered the survey may differ in some meaningful way from people who were invited to respond but chose not to participate.
You can calculate non-response error by comparing the characteristics of those who did respond with those who didn’t. Ideally, there will be no systematic difference. There are methods to detect whether non-responses are systematic or random.
Error Reduction Strategy: The most common ways of increasing response rates are by offering incentives, re-contacting targeted participants, and keeping surveys as short as possible.
4. Measurement Error
You can have great coverage, a large sample size, and fully complete responses, but you’ll always have to deal with the final horseman: measurement error. This error encompasses all the things that can go wrong with how you present questions and response options and how they might be misinterpreted by respondents. The gap between what we intend to measure and what results we get speaks to the validity of the survey.
Problems that cause measurement error include
- Misinterpreting questions
- Forgetting responses
- Unclear questions
- Ambiguous questions and wording
- Vague and improper response options
These measurement errors can lead to response bias (systematic error) and variability (less precision in the response). Both errors are visualized in Figure 4.

Figure 4: Visualization of the distinction between bias and variability.
Error Reduction Strategy: When possible, use standardized questions and response scales that have been refined to reduce measurement error along with other techniques to make questions and response options clearer.
Summary
When conducting a survey (or any other method that includes survey-like questions and sampling), watch for these four potential survey errors. Like the Apocalyptic four horsemen, you should strive to avoid all of them:
- Coverage errors: Not targeting the right people.
- Sampling error: Inevitable random fluctuations you get when surveying only a part of the sample frame.
- Non-response error: Systematic difference from those who don’t respond to all or some questions.
- Measurement error: The gap between what you want to measure and what you get due to bias and variability in responses.