 It looks like AI can “watch” videos. And if AI can watch videos, it can likely extract UI problems. That suggests it has the potential to support UX research.
It looks like AI can “watch” videos. And if AI can watch videos, it can likely extract UI problems. That suggests it has the potential to support UX research.
So maybe AI can “watch” a video and detect some problems. But if you run the same video through AI multiple times, do you get the same results?
Reliability matters. If AI produces different results each time, it becomes untrustworthy, no matter how convincing its reasoning sounds.
There are a lot of variables that can affect our assessment of reliability, including:
- AI models (Gemini, ChatGPT, Claude, Grok)
- Versions (models are changing monthly)
- LLM settings like temperature, which affect the randomness of the output
- Prompts: What you ask (and even how many times you ask)
There are a lot of variables to consider, but we have to start somewhere. So we did. In this article, we take a first step in assessing the reliability of AI problem detection. We examined how consistent two popular AI chatbots are at identifying usability problems from the same video.
Study Setup
We had two LLMs, ChatGPT-5.4 Thinking and Gemini 3 Flash Thinking, review the video and list the usability issues they discovered (four runs per LLM to check for within-LLM consistency; default settings only). Both are general-purpose LLMs for which MeasuringU has paid “pro” subscriptions (i.e., not free versions). Video 1 shows a 15-second clip of the full six-minute video.
Video 1: First 15 seconds of a participant searching for a sushi restaurant on the OpenTable website.
The task (visible at the bottom of the video) was to use OpenTable.com to:
“Please think aloud. Make a reservation for four people at a sushi restaurant in Denver, CO tomorrow anytime after 5:00pm. Make sure the restaurant you select is not at the lowest or highest price point. Of the restaurants that fit these criteria, look at their overall rating, customer reviews, and photos to select the one that is the most appealing to you. Go as far as you can in the reservation process until you are asked for your personal information or account details. DO NOT fully confirm the reservation. Write down the restaurant name and the time of the reservation. You will be asked about this information after the task.”
We used the following prompt:
“During a usability test, the facilitator must keep track of participant behaviors as they navigate through tasks on a website, mobile app, software program, etc. We’d like you to watch a video of a usability test where participants were asked to book a table at a Sushi restaurant. As you’re watching, please look for problems the participant has while attempting to complete the task. For example, you can document the path users take, describe issues they encounter as well as what on the website might be causing problems. If you understand these instructions, let me know and I’ll drag the video in for you to review. Are you ready for the video?”
The LLM response to this question was always some version of “Yes.”
In this study, we varied only the type of AI: ChatGPT and Gemini. The video, the prompt, and the LLM versions and settings were constant, but we plan to vary those variables in future studies.
Assessing Reliability
If you ask, AI will deliver (something). For each run, we compiled a list of usability problems that the AI model “discovered.”
For example, a problem noticeable in the video (and on the current OpenTable website) is that when entering “Denver” in the search field, the previously selected cuisine (sushi) was removed, making for a clumsy filter and search experience.
To assess the reliability (consistency) of their problem discovery, we computed the any-2 agreement between ChatGPT and Gemini and within each model. We treated the models like evaluators.
Any-2 agreement is a UX context-specific version of the Jaccard similarity coefficient (J), the ratio of the intersection of two binary measurements divided by their union. When there are more than two evaluators, the overall any-2 agreement is the average of the any-2 agreements for each pair of evaluators.
Computing Any-2 Agreement
Imagine that (Y and C) have independently created lists of usability issues where Y’s list has 14 issues, C’s list has 17, and their two lists have ten issues in common (Figure 1). Their any-2 agreement is the intersection (the ten issues they both discovered) divided by the union of both lists (14 + 17 − 10 = 21), which is 48% (10/21).
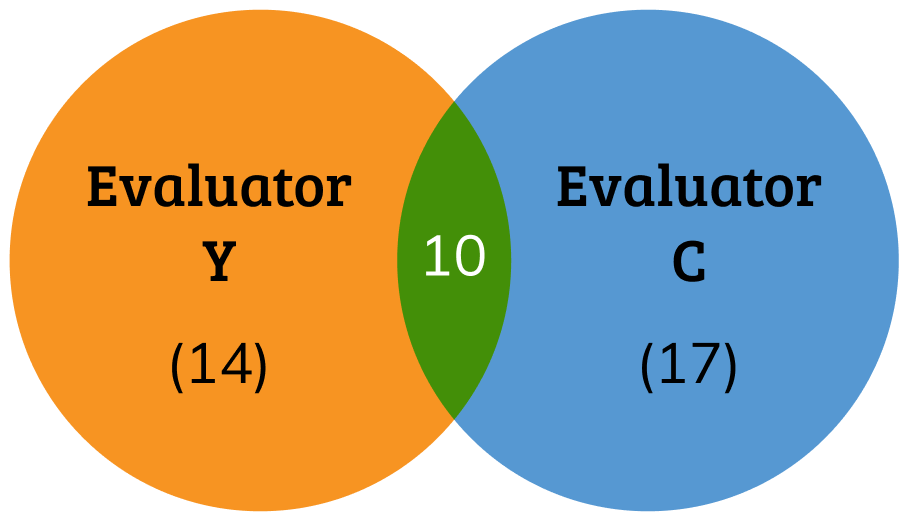
Figure 1: Venn diagram of problem discovery by two evaluators.
Due to the well-documented evaluator effect, we do not expect perfect agreement among UX researchers. In a controlled study like this (evaluators watching the same participants do the same tasks), our best estimate of typical any-2 agreement across multiple human evaluators (based on 12 evaluations) is 47%. (When studies are not controlled, the expected any-2 agreement is about 27%.)
This gives us a rough benchmark for assessing if an any-2 agreement is typical (around 50%), relatively low (around 25%), or relatively high (around 75%).
Within-Group Results
The first step in our analysis was to compute the mean any-2 agreement for each group of “evaluators” (ChatGPT, Gemini) to estimate the levels of within-group reliability.
ChatGPT Reliability Was Fair
Table 1 shows the combined problem list for the four runs of ChatGPT. Table 2 shows the any-2 agreements for each pair of runs.
| GPT # | GPT Problem List | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|---|
| 1 | Complex search field with placeholder text and unexpected behaviors significantly delayed user who selected sushi from search bar dropdown but for Dallas (default) instead of Denver | ||||
| 2 | Entering "Denver" in search field lost previous selection of sushi as cuisine | ||||
| 3 | Filters not helpful | ||||
| 4 | Scanning through 86 cuisines is effortful, then top that off by sushi not being in the list | ||||
| 5 | Surprised when typing sushi into search field did not lose current location | ||||
| 6 | Search results for sushi included many non-sushi restaurants | ||||
| 7 | Weak presentation of cuisine information in search results | ||||
| 8 | Participant seemed to miss price point filter—sorted on ratings and examined price points in descriptions | ||||
| 9 | Sorting by highest rated put many non-sushi restaurants at the top of the list | ||||
| 10 | UI pushes browsing without good decision support | ||||
| 11 | Selected result labeled seafood instead of sushi | ||||
| 12 | Task not completed because participant did not reach reservation form |
Table 1: ChatGPT evaluations problem list.
| Any-2 | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|
| Run 1 | x | 30% | 63% | 38% |
| Run 2 | 30% | x | 33% | 0% |
| Run 3 | 63% | 33% | x | 25% |
| Run 4 | 38% | 0% | 25% | x |
Table 2: Any-2 agreement for the ChatGPT evaluations.
With an overall any-2 agreement of 31%, the reliability of the ChatGPT evaluations was fair. None of the problems was identified on all four runs (5/12 were identified on three runs). Runs 2 and 4 had no problems in common.
Gemini Reliability Was Better
Table 3 shows the combined problem list for the four runs of Gemini. Table 4 shows the any-2 agreements for each pair of runs.
| Gem # | Gemini Problem List | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|---|
| 1 | Entering "Denver" in search field lost previous selection of sushi as cuisine | ||||
| 2 | Scanning through 86 cuisines is effortful, then top that off by sushi not being in the list | ||||
| 3 | Participant used Ctrl-F to search page for "sushi"—not found | ||||
| 4 | Participant seemed to miss price point filter—sorted on ratings and examined price points in descriptions | ||||
| 5 | Participant chose highest price tier | ||||
| 6 | Participant wanted to change sort to lowest rating first but not an option | ||||
| 7 | Seating options only presented after selecting time | ||||
| 8 | Set time to 5:10 | ||||
| 9 | Selected result labeled seafood instead of sushi |
Table 3: Gemini evaluations problem list.
| Any-2 | Run 1 | Run 2 | Run 3 | Run 4 |
|---|---|---|---|---|
| Run 1 | x | 38% | 67% | 80% |
| Run 2 | 38% | x | 38% | 43% |
| Run 3 | 67% | 38% | x | 80% |
| Run 4 | 80% | 43% | 80% | x |
Table 4: Any-2 agreement for the Gemini evaluations.
With an overall any-2 agreement of 57%, the reliability of the Gemini evaluations was good (3/9 problems identified in all four runs, 4/9 identified by at least three runs).
Between-Group Results
The second step in our analysis was to compute the mean any-2 agreement across LLMs to estimate the between-group reliability, shown in Table 5.
| Any-2 | Gem 1 | Gem 2 | Gem 3 | Gem 4 |
|---|---|---|---|---|
| GPT 1 | 40% | 40% | 33% | 40% |
| GPT 2 | 20% | 20% | 17% | 20% |
| GPT 3 | 40% | 75% | 33% | 40% |
| GPT 4 | 0% | 33% | 0% | 0% |
Table 5: Any-2 agreement between ChatGPT and Gemini evaluations.
With an overall any-2 agreement of 28%, the between-AI reliability was low (closer to 25% than to 50%).
Summary and Discussion
Along with the rest of the UX researcher community, we have a strong interest in the roles that AI might play in facilitating our work. Watching participants attempt to complete tasks is a fundamental but labor-intensive UX research activity, so any relief AI assistance might offer would be welcome.
As a first step to investigate the capability of ChatGPT-5.4 Thinking and Gemini 3 Flash Thinking of finding usability problems in videos, we collected evaluations of a single video (summarized as lists of usability problems), performing four runs with each LLM.
In this article, we evaluated any-2 agreement within each group of evaluations (ChatGPT, Gemini) and between the AIs. Our key findings were:
Gemini had good reliability, and ChatGPT’s was fair. The average any-2 agreement for ChatGPT was 31%. We expect this level of reliability when comparing different evaluators, different methods, or different users. It’s certainly lower than you’d want, but still at a level considered acceptable in our industry.
For Gemini, the average any-2 agreement was good at 57%. From the literature and our own research with human evaluators, 57% is above the mean of 47% and on the higher side of acceptability.
Between-group reliability for Gemini and ChatGPT was low. The any-2 agreement between ChatGPT and Gemini was low at 28%. That’s about 20 points below the average when examining the same video by different people. This result is not great.
Reliability isn’t accuracy. Are the problems identified by the LLMs as relevant as those discovered by a human evaluator? This question hasn’t been answered yet (a future analysis will). But to have accuracy (validity), we need to establish consistent (reliable) results, and at least for this video and prompt, the Gemini performance was sufficiently reliable.
Humans vs. AI coming soon. We’re just getting started with our analyses. In an upcoming article, we’ll compare any-2 agreement between these LLMs and a problem list generated by professional human UX researchers. Stay tuned.