 We use the seven-point Single Ease Question (SEQ®) frequently in our practice, as do many other UX researchers.
We use the seven-point Single Ease Question (SEQ®) frequently in our practice, as do many other UX researchers.
One reason for its popularity is the body of research that started in the mid-2000s with the comparison of the SEQ to other similar short measures of perceived ease-of-use, the generation of a normative SEQ database, and evidence demonstrating its strong correlation to task completion and task time.
Over time, different versions of the SEQ have appeared in the literature. Even in our own practice, it has evolved, so we’ve recently started studying whether some of these variants have different measurement properties, especially concerning means and top-box scores.
For example, we recently investigated mean and top-box differences for data collected using SEQ formats that differed only in the polarity of their response option endpoint labels (Very Difficult on the left for standard; Very Easy on the left for alternate, using a within-subjects Greco-Latin square design that, in addition to manipulating item format, also manipulated task difficulty). We found that the two formats produced very similar means, but there were some differences in top-box scores, especially when the task was difficult.
Another way in which the SEQ has changed in our practice is in the wording of the item stem (the part of the item that precedes the response options). As shown in Figure 1, the original wording was just “Overall, this task was:”. That works fine when presented in an online survey or printed form but is awkward to say verbally to participants in moderated usability tests. For consistency between our moderated usability testing and unmoderated usability testing/surveys, the wording we currently use is “How easy or difficult was it to complete this task?”.
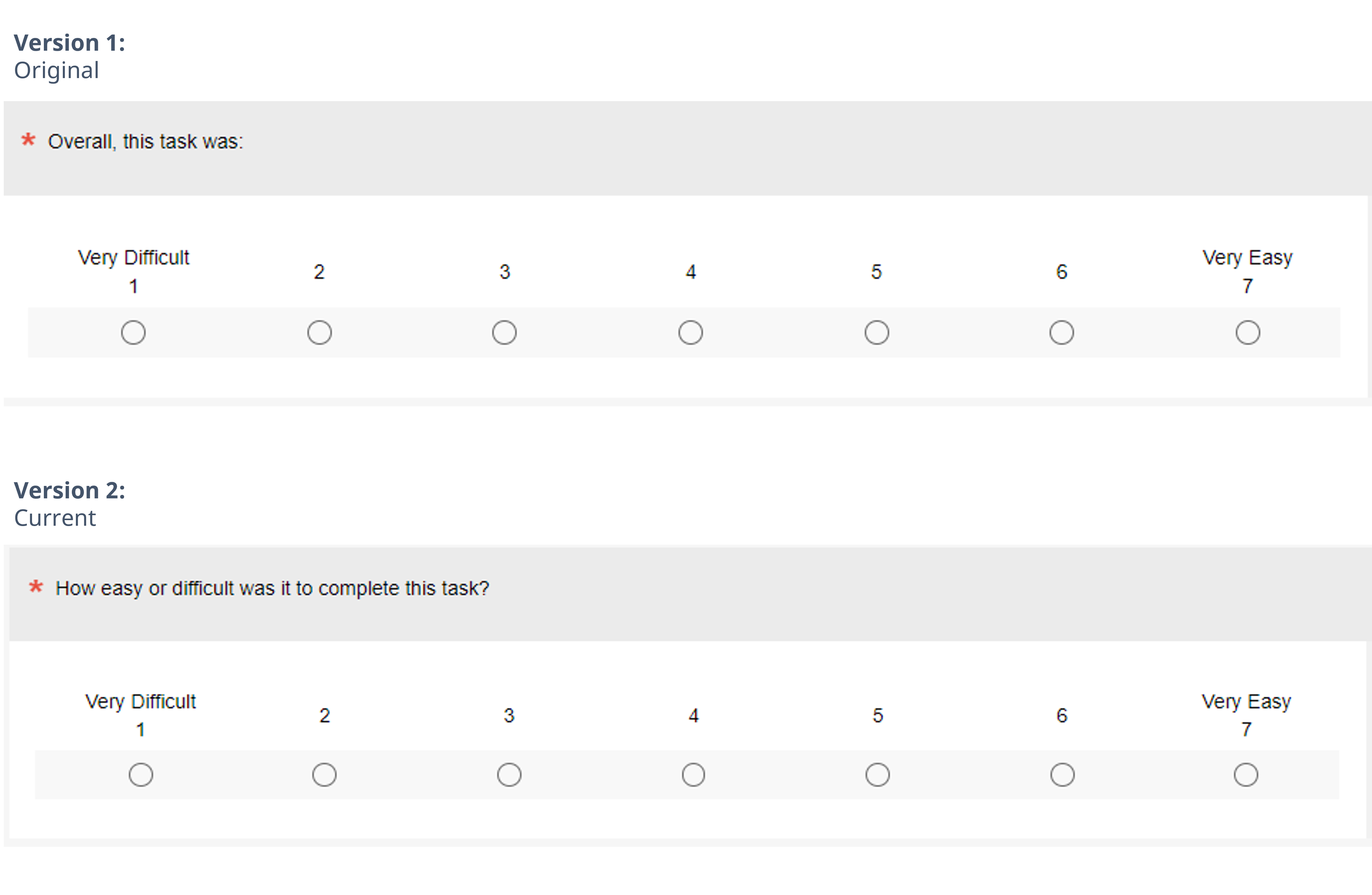
We often find that minor changes in wording have no consistent detectable effect on measurement with means or top-box scores, but we wanted to see whether this was the case with these SEQ variants because our current normative database includes data collected with both versions. It seemed to us that it was plausible that including the phrase “easy or difficult” in our current stem, with “easy” first, could slightly bias respondents toward selecting “Very Easy.”
So, we ran an experiment to find out.
Experimental Design: SEQ Original vs. Current Formats
Using our MUIQ® platform for conducting unmoderated remote UX studies, we set up a Greco-Latin experimental design to support a within-subjects comparison of original and current versions of the SEQ in the contexts of attempting easy and hard tasks.
- Easy: Find a blender on the Amazon website for under $50. Copy or remember the name of the blender brand.
- Hard: Please find out how much the monthly cost of an iPhone 12 with 64GB of storage with service for one line is on the AT&T website. Copy or remember the monthly cost (including all fees).
We collected data from 305 participants (sampled in April and May 2022 from a U.S. panel provider). After attempting each task, participants completed either the original or current version of the SEQ, following the experimental design. After completing both tasks, they indicated whether they preferred the original or current format.
In this experimental design, there were three independent variables:
- Item Format: Original or current, as shown in Figure 1
- Rating Context: Easy or hard task
- Order of Presentation: The Greco-Latin design had four orders of presentation.
- Original/easy then current/hard (n = 77)
- Original/hard then current/easy (n = 76)
- Current/easy then original/hard (n = 76)
- Current/hard then original/easy (n = 76)
Using this design, all participants attempted a hard and an easy task, and they saw both the original and the current version of the SEQ.
Participants were randomly assigned to one of the four orders of presentation. Across the experiment, this controls for the “nuisance” variable of order of presentation while enabling a balanced analysis of item format and task difficulty. It also enables a purely between-subjects analysis using data from the first condition participants experienced in their assigned presentation order.
Results
We conducted analyses of means and top-box scores, both with all the data (within-subjects) and just initial ratings (between-subjects). In this experiment, there were no differences in the significance of outcomes for within-subjects and between-subjects analyses.
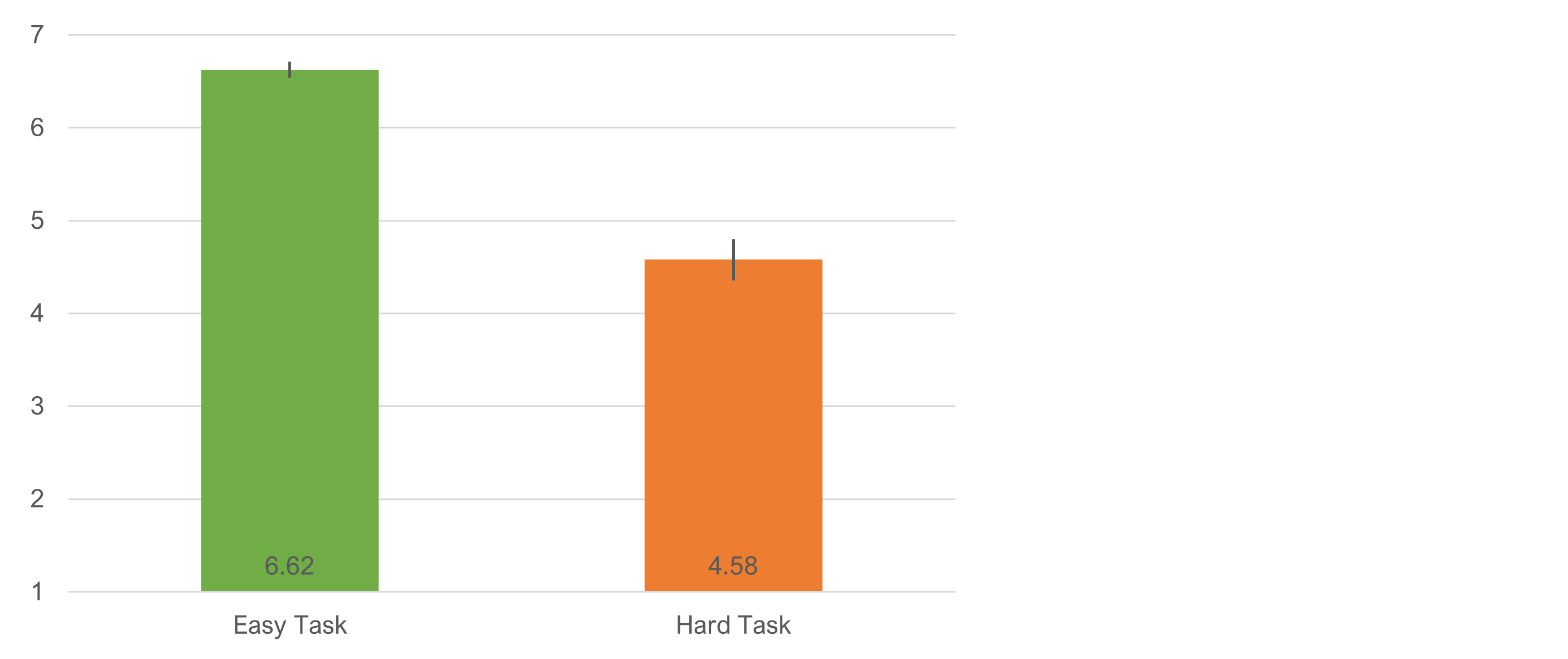
Was the Easy Task Perceived as Easier than the Hard Task?
We conducted a manipulation check to ensure the tasks differed in their levels of perceived ease. As shown in Figure 2, the difference in overall SEQ means for the easy and hard tasks was statistically significant (t(304) = 18.7, p < .0001) with an observed difference of 2.05 (34% of scale range) and 95% confidence interval from 1.83 to 2.26.
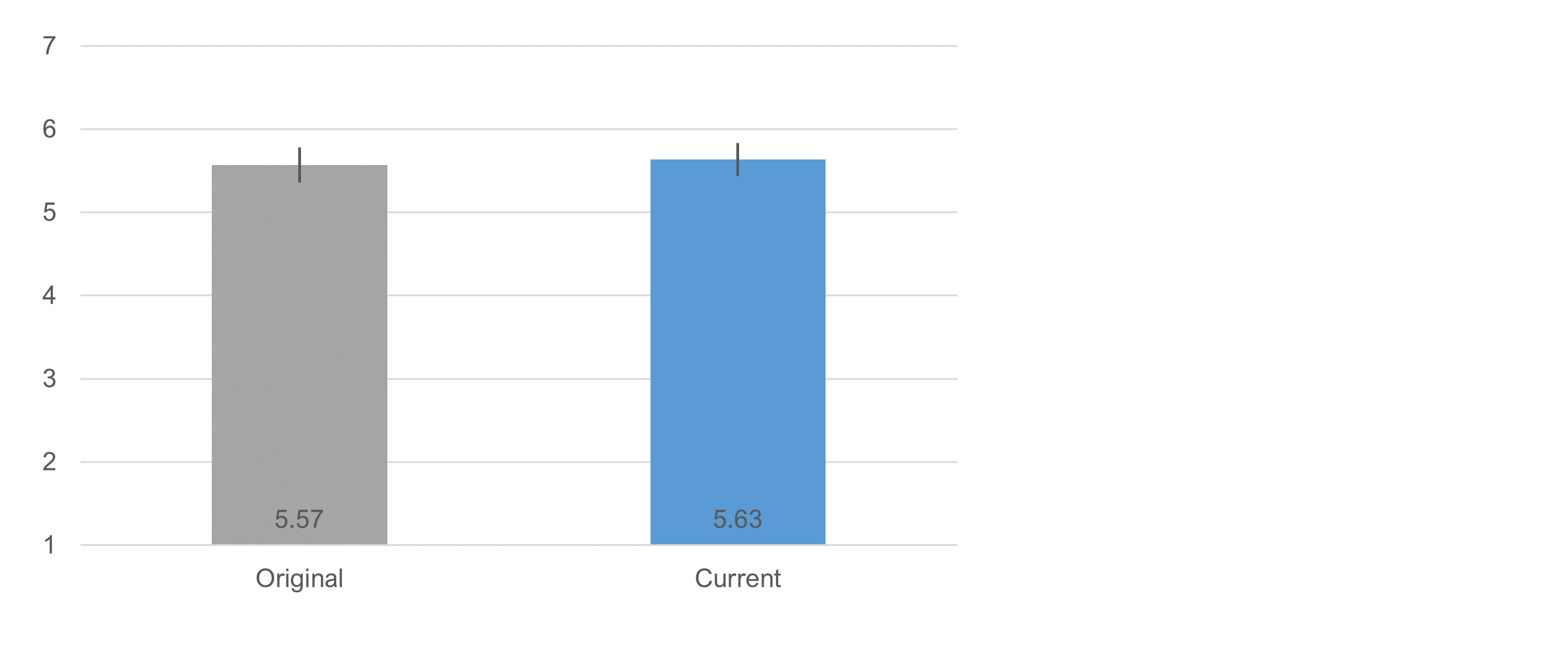
Did Item Format Affect the Means?
Figure 3 shows the overall difference in mean SEQ for the two SEQ formats, which was not statistically significant (t(304) = 0.41, p = .68) with an observed difference of .066 (1.1% of scale range) and 95% confidence interval from −0.25 to 0.38.
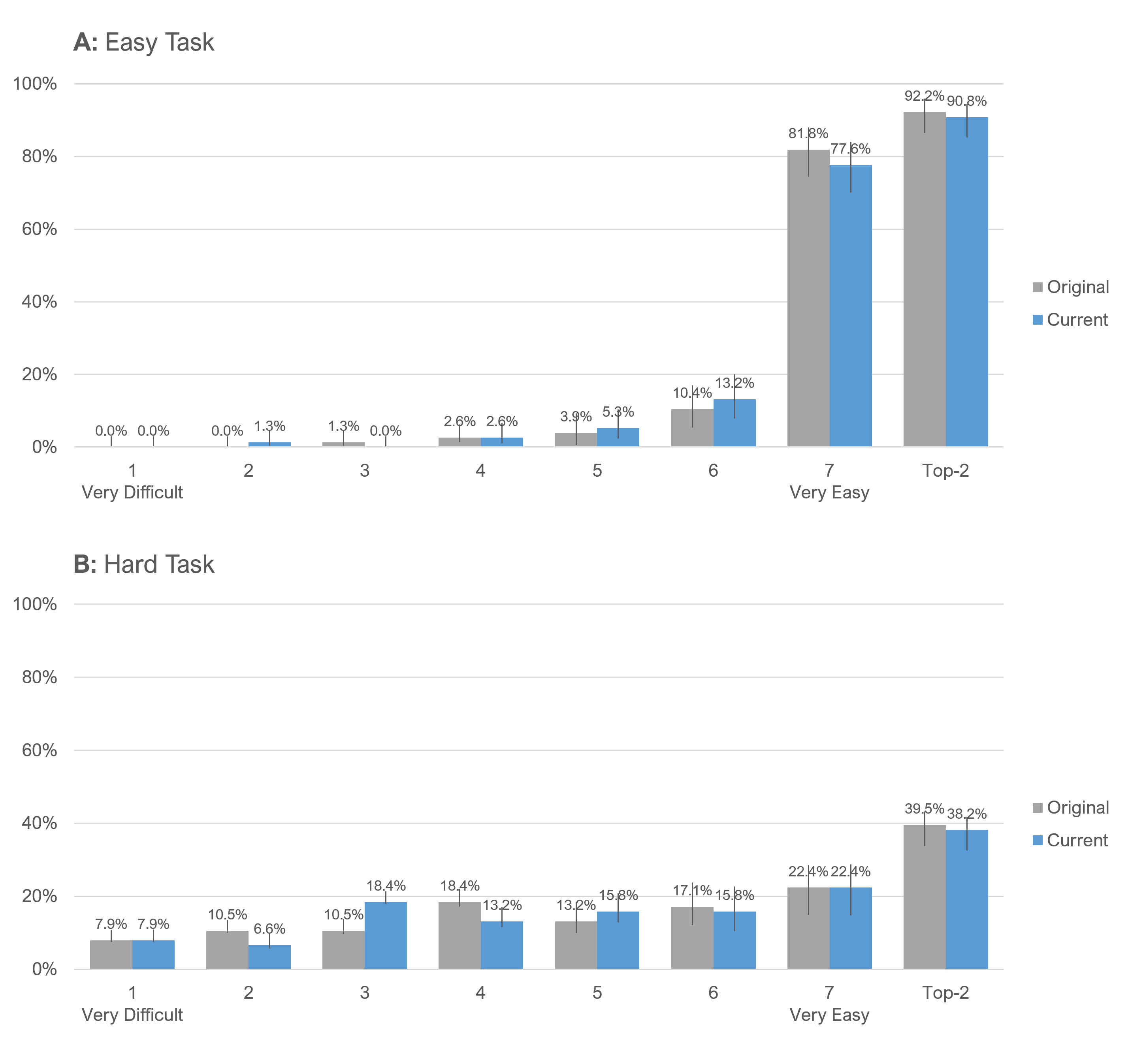
The differences between formats for the easy and hard tasks were also not significant, as shown in Figure 4 with details in Table 1.

| Task | t | df | p | Obs Diff | % Range |
|---|---|---|---|---|---|
| Easy | 0.35 | 304 | 0.72 | 0.022 | 0.4% |
| Hard | −1.04 | 304 | 0.30 | -0.166 | −2.8% |
Table 1: Comparisons of SEQ means for two item formats and two levels of task difficulty.
Did Item Format Affect Response Distributions?
Figure 5 shows the overall response distributions collapsed over task difficulty. Combined in this way, the distributions are similar, with no significant difference for top-box or top-two-box percentages (Table 2).
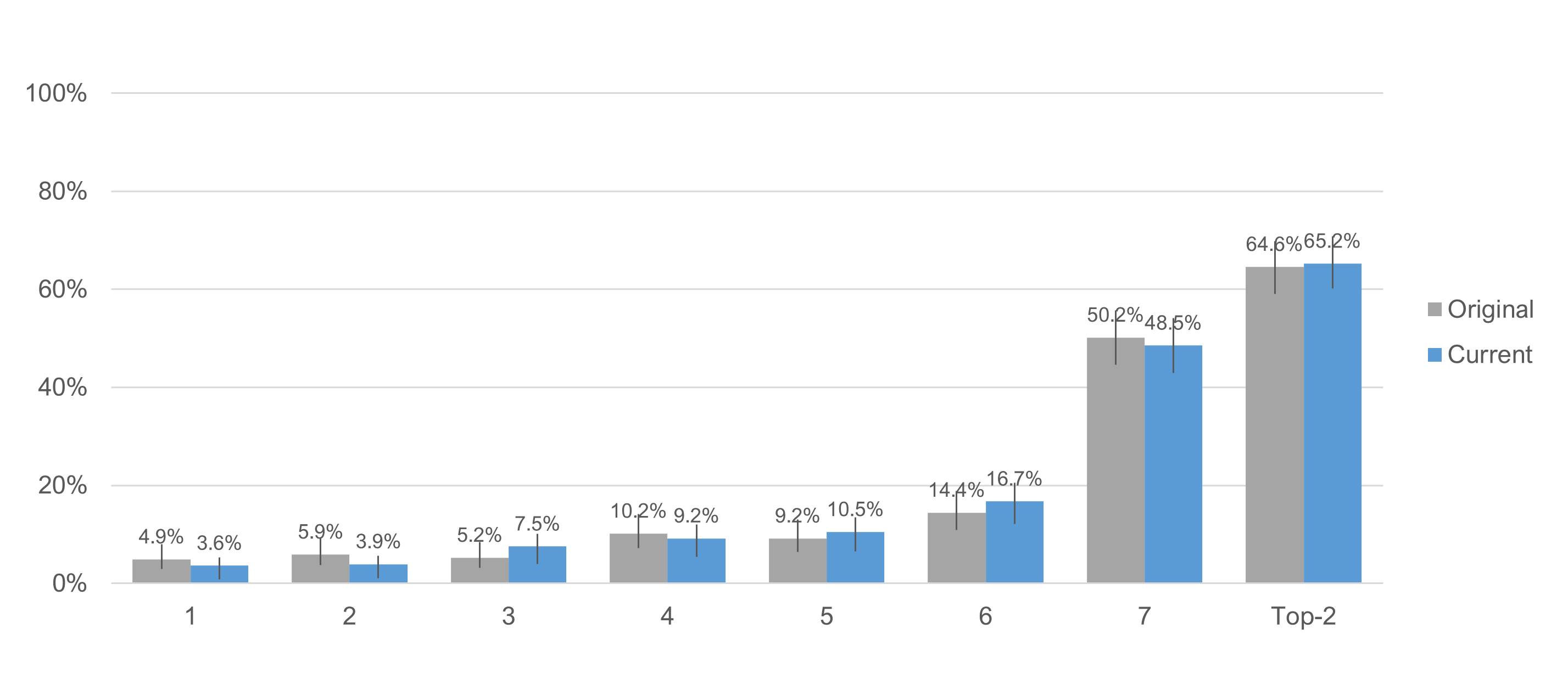
| Box Type | z | p | Obs Diff | Lower 95 | Upper 95 |
|---|---|---|---|---|---|
| Top-box | 0.40 | 0.69 | 1.6% | −6.3% | 9.6% |
| Top-2-box | 0.16 | 0.88 | 0.6% | −7.6% | 8.9% |
Table 2: Comparisons of SEQ top- and top-two-box scores for two item formats.
When analyzed to compare box scores for each format and each level of task difficulty, the results continued to be nonsignificant (Table 3, n−1 two-proportion tests).
| Task Type | Box Type | z | p | Obs Diff | Lower 95 | Upper 95 |
|---|---|---|---|---|---|---|
| Easy | Top-box | 0.296 | 0.77 | 1.5% | −8.3% | 11.2% |
| Hard | Top-box | 0.299 | 0.76 | 1.5% | −8.1% | 11.1% |
| Easy | Top-two-box | 0.183 | 0.85 | −0.6% | −7.1% | 5.9% |
| Hard | Top-two-box | 0.189 | 0.85 | −1.1% | −11.9% | 9.8% |
Table 3: Comparisons of SEQ top- and top-two-box scores for two item formats and two levels of task difficulty (for all comparisons, n = 305).
As shown in Figure 6 and Table 4, differences in box scores were similarly nonsignificant but a bit more extreme when analyzing data from just the first task condition in the experimental design (between-subjects) with n−1 two-proportion tests, especially for the easy task.
| Task Type | Box Type | z | p | n | Obs Diff | Lower 95 | Upper 95 |
|---|---|---|---|---|---|---|---|
| Easy | Top-box | 0.64 | 0.52 | 153 | 4.2% | −8.6% | 12.7% |
| Hard | Top-box | 0.00 | 1.00 | 152 | 0.0% | −13.2% | 13.2% |
| Easy | Top-two-box | 0.31 | 0.75 | 153 | 1.4% | −7.8% | 10.6% |
| Hard | Top-two-box | 0.17 | 0.87 | 152 | 1.3% | −14.0% | 16.6% |
Table 4: Between-subjects comparisons of SEQ top- and top-two-box scores for two item formats and two levels of task difficulty.
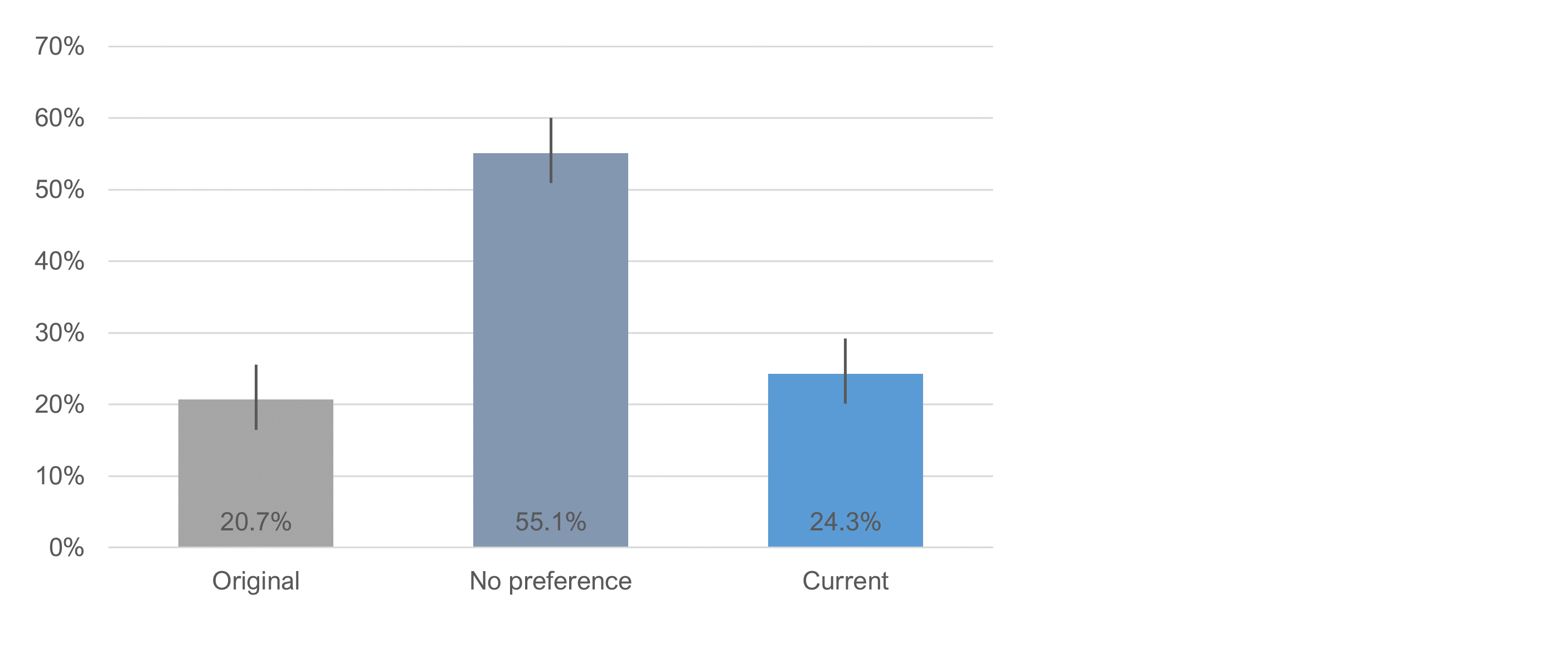
Which Version Did Participants Prefer?
After attempting both tasks, participants indicated which item format they preferred. As shown in Figure 7, over half of the participants had no preference. For those who had a preference, there was a nominally slight but statistically nonsignificant preference for the current version (n−1 two-proportion test, z = 1.07, p = .29, observed difference of 3.6% with 95% confidence interval from −3.0 to 10.2%).
Summary and Takeaways
We conducted an experiment to check potential differences in measurement properties between two SEQ formats that had the same response options but different stems—the original version (“Overall this task was:”) and our current version (“How easy or difficult was it to complete this task?”). Over several years, we evolved from the original to our current version because it works better in moderated studies and equally well in unmoderated studies.
We conducted this experiment because it seemed plausible that including the phrase “easy or difficult” in our current stem, with “easy” first, could slightly bias respondents toward selecting “Very Easy.”
What we found, however, was that across many ways of analyzing the data, there were no statistically significant differences (in fact, the smallest p-value across the analyses was .30).
The largest nominal (nonsignificant) finding was a top-box difference between the original and current SEQ formats of 4.2% for the easy task (Figure 6, Panel A). For that comparison, the original version had a higher percentage selection of Very Easy, which is the opposite of what you would expect if the current item stem (that includes “easy or difficult”) tended to bias respondents toward selecting “Very Easy.” This was the most extreme outcome—across all analyses, most differences were closer to 1.5% usually, but not always, with nominally higher scores for the original version.
Because participants in the experiment used both formats during the task sessions, we asked them which they preferred. Over half of the participants had no preference. For those who had a preference, votes were about evenly split between the two versions, with a nominal (but not significant) preference for the current version.
Takeaway 1: UX practitioners can consider these SEQ formats to be both mean and distribution equivalent. We found no evidence of consistent differences due to the wording differences in these item stems.
Takeaway 2: Even though these appear to be equivalent SEQ forms, we recommend using our current version because it works better than the original in moderated usability studies and equally well in unmoderated studies. Consequently, it’s the default wording in our MUIQ platform.