 Researchers love to argue about the “right” number of points to use in a rating scale response option.
Researchers love to argue about the “right” number of points to use in a rating scale response option.
Is the right number five, seven, three, ten, or eleven? The opinions often exceed the data for helping drive the decisions. When there are data, they are often hard to generalize, or they don’t really support the position being held by the author.
Over the last hundred years, researchers have used many different criteria to determine the optimal number of response options for rating scales:
- Reliability
- Validity
- Sensitivity
- Ease of use
- Preference
- Information processing/discriminability
One argument we recently encountered for using fewer response options in rating scales was based on data that showed people just don’t use all the available options in long scales.
This is a plausible argument making a case for fewer options, and it was supported by some data. In this article, we review that data and discuss it, and then present findings from our own analysis that demonstrates usage of all available response options—even for eleven-point items.
Not All Response Options Are Used … Does It Matter?
In their book Survey Scales, Johnson and Morgan (2016) advised against using too many scale points, which “might result in respondents experiencing problems discriminating the scale points” (p. 75). In a previous article, we reviewed the data on which they based this advice. We concluded that the fundamental discriminability problem in the research they cited was due to too many labels rather than too many points.
We were intrigued by Johnson and Morgan’s reinterpretation of findings published by Dawes (2008). In the Dawes study, participants were presented with either a five-, seven-, or ten-point scale for the same eight purchasing items. The study was conducted over the phone with participants instructed “to ‘please answer using the scale from 1 to X where 1 equals strongly disagree and X equals strongly agree’. X was either 5, 7, or 10 depending on the treatment group” (p. 67).
After rescaling all the items to ten points, Dawes found comparable means across the eight items for all three item formats. The study also found that if a scale with more response options was administered, respondents used more response options, a finding that Dawes interpreted as favoring scales with more points.
Johnson and Morgan, however, noted that while the number of points used increased for the longer scales, the percentage of the available points used by individual respondents decreased from 58% to 40% (see Table 1), and they used this outcome to argue against scales with more points.
| Points | # Used | % Used |
|---|---|---|
| 5 | 2.9 | 58% |
| 7 | 3.6 | 51% |
| 10 | 4.0 | 40% |
Table 1: Average number of points used by respondents across eight items using five-, seven-, or ten-point variations (phone administered, n = 185).
We don’t find this argument compelling for at least two reasons. First, while the percentage of points used certainly decreased for items with more points (from 58% to 40%), the average number of points used still did increase (from 2.9 to 4.0). That suggests that if you provide more points, participants will use them, albeit at a rapidly diminishing rate (imagine if there were a hundred points). But that’s what we’d expect given some of the foundational work on scale points from Nunnally (1978). Nunnally reported that as you increase the number of points, scale reliability increases substantially at first but slows as it approaches an asymptote. (Technically, this is called a monotonic increase with diminishing returns.) But we don’t expect the reliability to decrease with more points, and the Dawes study shows a small increase in usage of scales (an indicator of reliability), as respondents have more points with which to express their opinions.
The second reason we don’t see this as a compelling argument is that respondents were presented with eight related items in the scale (e.g., “When I am in a shop I will always check prices on alternatives before I buy” and “When I buy or shop, I really look for specials”). While Dawes did not report the correlations among the items, it’s likely that such similar items would be highly correlated, so it’s not surprising that individual respondents did not use the full range of response options. A more interesting research question is the extent manipulating the number of options affects the response distributions of samples of respondents. But it would be good to use a more diverse set of data to investigate this.
{kind=link}
Data Set 1: Five-, Seven-, and Eleven-Point Usage from UX Data
We conduct regular SUPR-Q® studies with hundreds of respondents to refresh our normative percentile database and report on the UX of websites across common industries. The datasets include items from multiple questionnaires that have different numbers of response options (UX-Lite™ has five, Brand Attitude has seven, and Likelihood-to-Recommend (LTR) has eleven).
Tables 2, 3, and 4 show the overall response distributions for these items from our three most recent SUPR-Q retrospective studies: Auto Insurance, Food Delivery, and Mass Merchants.
| UX-Lite: Ease | 1 | 2 | 3 | 4 | 5 | n |
|---|---|---|---|---|---|---|
| Auto Insurance | 3 | 8 | 41 | 109 | 140 | 301 |
| Food Delivery | 1 | 3 | 25 | 81 | 102 | 212 |
| Mass Merchants | 4 | 12 | 41 | 183 | 222 | 462 |
| Total | 8 | 23 | 107 | 373 | 464 | 975 |
| UX-Lite: Useful | 1 | 2 | 3 | 4 | 5 | n |
|---|---|---|---|---|---|---|
| Auto Insurance | 2 | 6 | 47 | 117 | 129 | 301 |
| Food Delivery | 2 | 6 | 41 | 76 | 87 | 212 |
| Mass Merchants | 7 | 10 | 58 | 192 | 195 | 462 |
| Total | 11 | 22 | 146 | 385 | 411 | 975 |
Table 2: Response distributions for the two five-point items of the UX-Lite; green indicates used, yellow indicates not used.
| Brand Attitude | 1 | 2 | 3 | 4 | 5 | 6 | 7 | n |
|---|---|---|---|---|---|---|---|---|
| Auto Insurance | 1 | 1 | 5 | 37 | 75 | 107 | 75 | 301 |
| Food Delivery | 1 | 7 | 7 | 40 | 66 | 62 | 29 | 212 |
| Mass Merchants | 0 | 5 | 11 | 67 | 95 | 155 | 129 | 462 |
| Total | 2 | 13 | 23 | 144 | 236 | 324 | 233 | 975 |
Table 3: Response distributions for the seven-point Brand Attitude item; green indicates used, yellow indicates not used.
| LTR | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Auto Insurance | 3 | 0 | 4 | 4 | 9 | 14 | 31 | 46 | 73 | 51 | 66 | 301 |
| Food Delivery | 3 | 1 | 5 | 10 | 7 | 20 | 29 | 35 | 37 | 31 | 34 | 212 |
| Mass Merchants | 9 | 1 | 6 | 5 | 8 | 40 | 32 | 57 | 88 | 86 | 130 | 462 |
| Total | 15 | 2 | 15 | 19 | 24 | 74 | 92 | 138 | 198 | 168 | 230 | 975 |
Table 4: Response distributions for the eleven-point LTR item; green indicates used, yellow indicates not used.
Across the three surveys (n = 975), every option was selected at least once. For the five-point items, every option was selected in each survey. For the seven- and eleven-point items, there was one survey in which one response option was not used, but all options were used in the other two surveys.
Data Set 2: Comparing Three to Eleven UMUX-Lite Response Options
A reanalysis of data from a recently published study (Lewis, 2019) on manipulating the number of response options provides a unique opportunity to further explore this issue. In the study, respondents rated recent interactions with auto insurance websites using one of four versions of the UMUX-Lite. This is a standardized questionnaire with two items, one assessing perceived ease-of-use and the other assessing perceived usefulness. Each respondent completed both UMUX-Lite items in their assigned version.
All Points Used across All Versions
The versions differed only in the number of response options: three, five, seven, or eleven. After averaging the items and rescaling to a standard UMUX-Lite 0–100-point scale, there were no significant differences among the UMUX-Lite means. Table 5 shows the response distributions for each format (different numbers of response options) and each item of the UMUX-Lite (Ease and Useful).
| UX-Lite: Ease | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 points | NA | 2 | 19 | 33 | NA | NA | NA | NA | NA | NA | NA | 54 |
| 5 points | NA | 1 | 0 | 12 | 15 | 36 | NA | NA | NA | NA | NA | 64 |
| 7 points | NA | 2 | 1 | 5 | 2 | 15 | 21 | 20 | NA | NA | NA | 66 |
| 11 points | 0 | 1 | 1 | 1 | 3 | 4 | 3 | 8 | 13 | 10 | 17 | 61 |
| UX-Lite: Useful | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 points | NA | 2 | 16 | 36 | NA | NA | NA | NA | NA | NA | NA | 54 |
| 5 points | NA | 2 | 3 | 3 | 17 | 39 | NA | NA | NA | NA | NA | 64 |
| 7 points | NA | 2 | 2 | 2 | 5 | 7 | 23 | 25 | NA | NA | NA | 66 |
| 11 points | 2 | 1 | 1 | 0 | 0 | 4 | 0 | 8 | 11 | 15 | 19 | 61 |
| Combined | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 points | NA | 4 | 35 | 69 | NA | NA | NA | NA | NA | NA | NA | 108 |
| 5 points | NA | 3 | 3 | 15 | 32 | 75 | NA | NA | NA | NA | NA | 128 |
| 7 points | NA | 4 | 3 | 7 | 7 | 22 | 44 | 45 | NA | NA | NA | 132 |
| 11 points | 2 | 2 | 2 | 1 | 3 | 8 | 3 | 16 | 24 | 25 | 36 | 122 |
Table 5: Response distributions from Lewis (2019), individual UMUX-Lite items and combined; green indicates used, yellow indicates not used.
The sample sizes for the conditions in this study were much smaller than those in our SUPR-Q studies (~55 vs. ~250), so it’s not surprising that a few items did not have responses for each option (Ease: Option 2 of 5; Ease: Option 0 of 11; Useful: Options 3, 4, and 6 of 11). Even so, combined across just two items, respondents used all response options for all item formats.
Bottom and Top Box
Certain points in a rating scale tend to take on more meaning (e.g., more extreme attitudes tend to be better predictors of behavior), so we examined these distributions in more detail. Table 6 summarizes the distributions, showing the percentage of response options for the lowest option (e.g., bottom-box score); for the percentage of responses below the midpoint, at the midpoint, and above the midpoint; and for the highest option (top-box score), averaged across the items.
| Points | Lowest | Below Mid | Mid | Above Mid | Highest |
|---|---|---|---|---|---|
| 3 | 3.7% | 3.7% | 32.4% | 63.9% | 63.9% |
| 5 | 2.4% | 4.7% | 11.8% | 83.6% | 58.6% |
| 7 | 3.0% | 10.6% | 5.3% | 84.1% | 34.1% |
| 11 | 1.7% | 8.2% | 6.6% | 85.3% | 29.5% |
Table 6: Summary of response distributions from Lewis (2019).
The bottom-box scores were similar for all four item formats, consistent with the typical skew of these types of measurement. The distributions of the middle value of the scales were greater when there were only three response options, presumably due to respondents with less intense attitudes avoiding the maximum rating of 3. Likely for the same reason, percentages above the midpoint were higher for five, seven, and eleven response options.
More Ceiling Effects for Fewer Points
As shown in Figure 1, the top-box distributions were similar for three- and five-point scales, but they dropped significantly for seven- and eleven-point scales, which had similar response patterns. In other words, when there were only one or two points of discrimination above the midpoint, a ceiling effect concealed differences in the levels of positive attitude toward the websites. This result is consistent with the practice of using at least seven response options for single-item scales to ensure accurate measurement of extreme attitudes. When multiple items are combined to produce a score (as in the UMUX-Lite, UX-Lite, SUS, and SUPR-Q), because the combination effectively has more points of discrimination, the number of response options per item is less important.
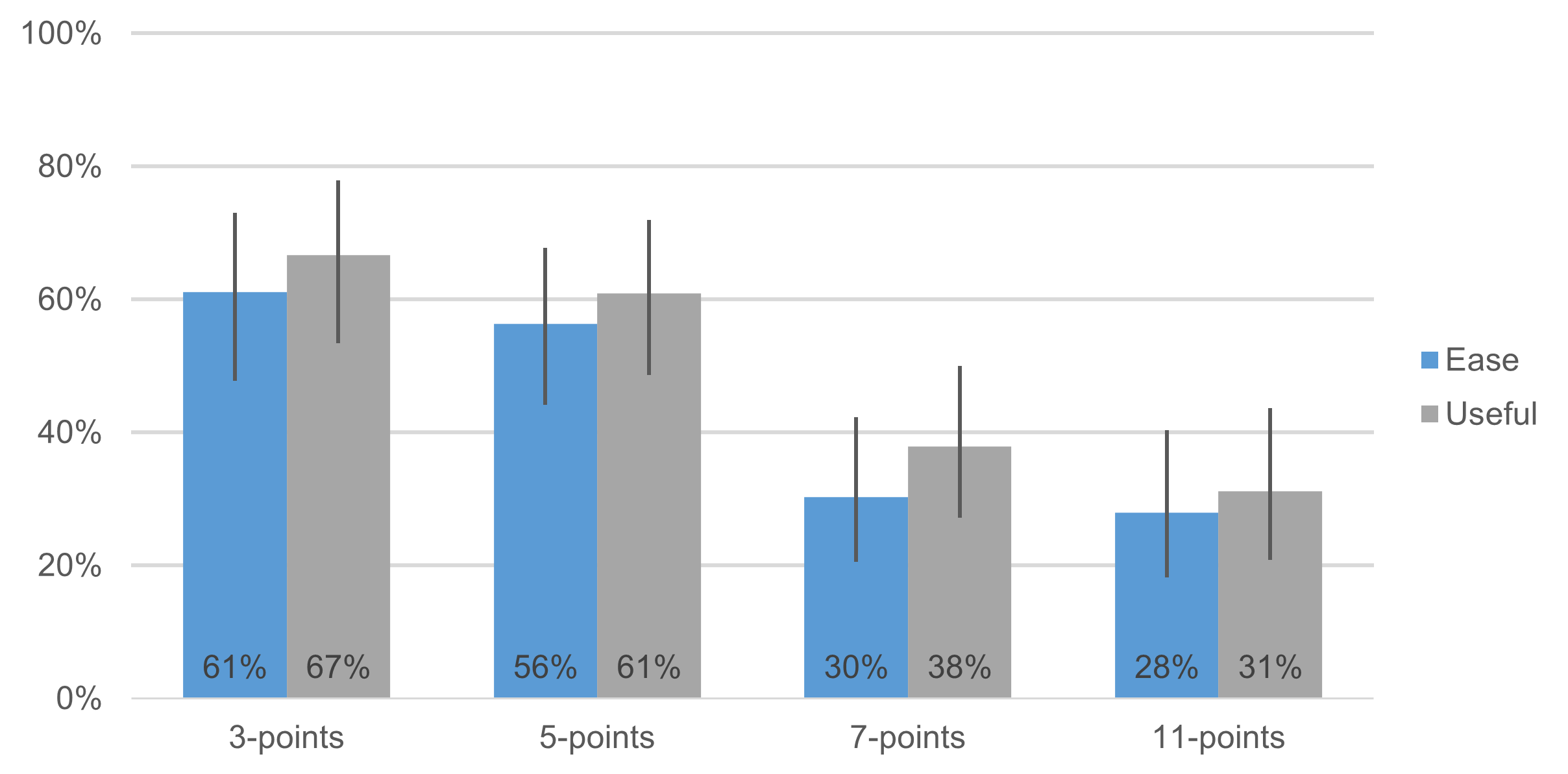
Figure 1: Distributions of top-box scores for both UMUX-Lite items and the four-item formats.
Summary and Discussion
There are many opinions about the “right” number of scale points. Fortunately, some of those arguments have data to help justify positions. Johnson and Morgan (2016) claim that respondents won’t use all options when presented with more than five or seven points and suggest that researchers use fewer response options in rating scales. To support the claim, the authors cited a study in which participants used a decreasing percentage of options in a telephone survey as the number of points increased from five to eleven.
To further investigate this claim, we examined two independent data sources containing responses from over a thousand participants. We found that respondents used all scale points for response scales with three, five, seven, and eleven points. These results add to the growing body of evidence that respondents are not confused by large numbers of response options and, across samples, tend to use all available response options for agreement scales with as many as eleven points.
We also found evidence that supports the practice of using at least seven response options for single-item measures (e.g., the Single Ease Question). In UX research, it’s common for respondents to have generally favorable attitudes toward the products or services being rated. When there are only three or five response options, this skewness leads to a ceiling effect with the most favorable option, which is measured as a top-box score.
Finally, a note of caution to researchers looking for guidance when crafting survey questions and response options. It’s neither possible nor practical for researchers to conduct their own research each time they want to know how changes to scales could affect measurements. They understandably turn to survey books or search the web for answers to their questions, reading blogs from sources with varying credibility or tracking down peer-reviewed research.
Books, while they are excellent sources of depth on a topic, do not necessarily treat each topic with the same level of careful research. As we’ve reviewed various books, it has become clear a significant amount of caveat emptor needs to be involved in the recommendations contained in those books. To be fair, it is good practice for UX researchers to read survey design books to advance their skills, but it is important to read them critically (as we expect you to read our blog articles critically).