 Unmoderated testing platforms allow for quick data collection from large sample sizes.
Unmoderated testing platforms allow for quick data collection from large sample sizes.
This has enabled researchers to answer questions that were previously difficult or cost prohibitive to answer with traditional lab-based testing.
But is the data collected in unmoderated studies, both behavioral and attitudinal, comparable to what you get from a more traditional lab setup?
Comparing Metrics
There are several ways to compare the agreement or disagreement of metrics. To understand how comparable different testing methods are, it helps to understand how to compare metrics.
The following table shows an example of seven-point rating scale data collected at the task level from unmoderated (Unmod column) and moderated (Mod column) studies for two tasks and the different ways agreement can be reported (mean difference, mean absolute difference, and correlation).
| Task | UnMod | Mod | Raw Diff | %Diff | ABS Diff | ABS Diff% |
|---|---|---|---|---|---|---|
| 1 | 6.7 | 6.5 | 0.2 | 3% | 0.2 | 3% |
| 2 | 6.3 | 6.6 | -0.3 | -5% | 0.3 | 5% |
| Mean | -0.05 | -1% | 0.25 | 4% |
Mean difference: Averaging the raw difference for both tasks (0.2 and -0.3 in the Raw Diff column) gets you a mean difference of -0.05 points. The main drawback with this approach is that positive and negative differences offset each other and make the average difference seem small. The difference can also be expressed as a percentage (% Diff column), which shows that the unmoderated scores are 3% higher than the moderated scores for Task 1 (6.7 vs. 6.5) and 5% lower for Task 2 (6.3 vs. 6.6). The average of these differences is -1%.
Mean absolute difference (MAD): Taking the absolute value of the difference for each task avoids the problem of positive and negative differences cancelling out. The ABS Diff column shows that the MAD is 0.25 for both tasks, or a percent difference (ABS Diff % column) of 4%, which shows larger disagreement than the mean difference of 1%.
Correlation: The correlation at the task level provides an idea about how much the scores vary but not necessarily how closely they track (correlations not shown in the table). High correlation and high agreement are generally above r = .7 and no correlation is r = 0, and low agreement would be anything below r = .10 (and anything negative). You can have low or no correlation but still have values that are close, which is one of the limitations of using correlation, especially when there are only a few values to compare and the data is restricted to a narrow range.
Existing Comparisons
Given the popularity of unmoderated testing, there’s surprisingly little published on the differences between moderated and unmoderated metrics in the literature. Most of what has been published focuses more on how usability problem identification may differ between the methods (see for example Varga, 2011 and Andreasen et al., 2007) or even debates for the merits of either method without examining the data.
Tullis Experiment 1
One of the earliest and more insightful comparisons was published by Tom Tullis and team in 2002. In this paper they describe two experiments they conducted while at Fidelity and examine the differences in the metrics.
In the first experiment, 8 lab-based participants and 29 unmoderated participants (employees of Fidelity) attempted the same 17 tasks on the company’s intranet. Tullis et al. looked at the average completion rates, time, and nine post-study ease scores.
Completion Rates
They reported a high correlation between task completion rates (r = .70), with a mean difference of 4% (60% lab vs. 64% unmoderated) and MAD of 15%. The authors noted that the same tasks from both methods were identified as difficult (showing comparability); see Figure 1.
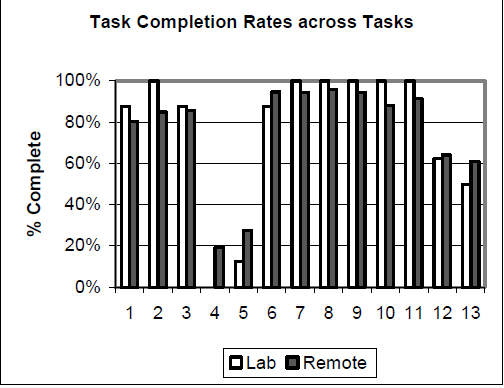
Figure 1: Completion rates figure from Tullis et al., study 1.
Task Time
Task time for all attempts (success and failure) differed a bit more but still had a high correlation (r = .65). The average lab time across all tasks was 147 seconds vs. 164 seconds for the unmoderated portion (a 12% mean difference), but this masked some of the variability within each task as the MAD was 28%, with one task taking more than twice as long on the unmoderated study (38 seconds moderated vs. 101 seconds unmoderated). Despite the larger differences, similar tasks were identified as taking longer on both methods.
Attitudinal Data
For attitudinal data on nine rating scales (e.g. ease, visual appeal) there was an 0.8 point difference (1.46 moderated vs. 0.67 unmoderated). On a six-point scale ranging from -3 to 3, this is a 13% difference and MAD of 14%. Participants generally rated the unmoderated tasks lower than the lab (r = .49) but there was less consistency.
Tullis Experiment 2
In their second study, Tullis et al. revised the tasks to have clearer task success criteria to reduce differences between methods—which they generally were able to. They tested a prototype with 8 lab-based participants (Fidelity employees) and 88 unmoderated participants on 13 tasks.
Completion Rate
This time average task completion rates across the 13 tasks had a very high correlation ( r = .98). The mean difference was actually 0% and MAD 8%.
Task Time
Average task time data was also very similar across methods (r = .94). The mean difference was 4% (155 sec. vs. 161 sec.) and the MAD 19% with the largest difference being a ratio of about 1.6 to 1 (75 seconds in the lab vs. 124 seconds unmoderated).
Attitudinal Data
The post-study subjective data showed a 0.3 points (5%) on the same six-point scale and a MAD of 9%. One task had a difference of 1.5 points (25% of the range of the six-point scale). There was much less correspondence between the ratings on the unmoderated and moderated, with different tasks being identified as harder or easier and a corresponding low and not statistically significant correlation (r = .04).
CUE-8
I also examined the difference between moderated and unmoderated methods as part of Rolf Molich’s Comparative Usability Evaluation CUE-8 in 2009. Rolf asked independent teams to test five tasks on the Budget rental car website. We then compared our results.
In an earlier article, I discussed these findings in detail. I collected data using a traditional in-person moderated lab study with 12 participants and another team collected data independently for the same tasks on the Budget.com website using an unmoderated lab as part of CUE-8 (over 300 participants). The other team as it happens was led by Tom Tullis.
In that examination, I found generally modest differences (good agreement) for completion rates and post-study SUS scores, but more disagreement on task time:
- Task completion: 1% average difference, 7% MAD, and correlation of r = .24
- Task time: 28% mean difference, 31% MAD, and correlation of r = .88
- Post-study SUS: A 1.6 point difference or 2% difference
Cross Platform Financial Services Study
We recently conducted a large-scale benchmark on a financial services company’s desktop website, mobile website, and native application. We first collected data in our labs with 10 participants (n = 30) and then replicated the study on MUIQ with 150 US-based participants per platform (450 total). Participants completed eight tasks on one of the platforms in randomized order.
The moderated sessions lasted one hour and took place in Denver, CO. We collected the task-level metrics of completion rate, post-task ease (using the SEQ), and task completion time (only from successfully completed participants). The recruiting criteria and tasks were the same for the moderated and unmoderated portions of the study (customers of this financial institution with some platform experience).
The goal of this study wasn’t to attempt to match the lab with the unmoderated group but to use the lab to identify usability issues and the unmoderated group to generate more precise metrics from a larger sample. As such there was more opportunity for variability (e.g. care wasn’t taken to ensure equal ways of validating the task and recording time as in the Tullis studies). But it’s also probably a more ecologically valid comparison as it mirrors more realistic use of lab versus unmoderated data. The data isn’t completely independent because very similar tasks were used across all three studies.
In general, we found similar results to Tullis and the CUE data. The average completion rate difference across the 24 tasks (8 on each platform) was a surprisingly low -3% difference (slightly lower completion rates on unmoderated).
Figure 2 shows an example of the completion rates between the unmoderated and moderated studies for eight tasks on the desktop experience.
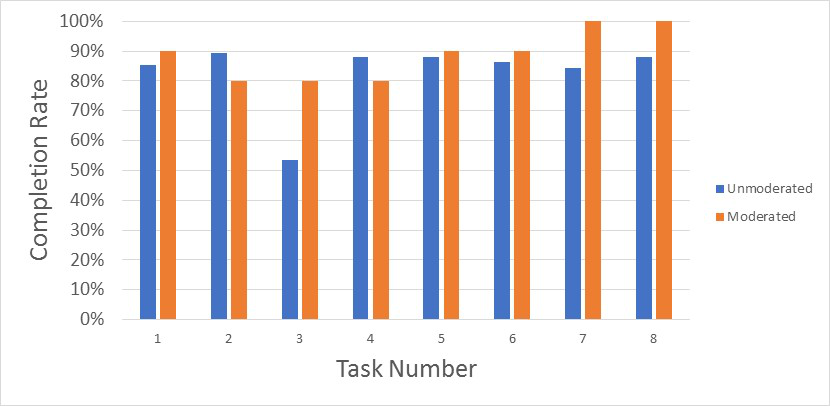
Figure 2: Difference in completion rates for eight tasks on a desktop study between moderated and unmoderated setups.
I then aggregated the data across all 24 tasks and metrics (8 on each platform) and graphed the differences in dot plots in Figure 3.
The average difference in perceived ease (SEQ) across the 24 tasks was 0.18 points, or less than 3% on a seven-point scale. Task time was again showing the most variation with an average difference of 21%, with some tasks showing much larger differences (e.g. 156% different).
Across the three metrics, the differences were not statistically different from 0. Figure 3 shows ease and time score difference are slightly positively biased (more dots above 0), suggesting a slight trend toward unmoderated studies being perceived as slightly easier and taking slightly longer. Completion rates are slightly lower on unmoderated studies.



Figure 3: Difference in completion rates, ease (SEQ), and task time between unmoderated and moderated data (24 tasks across three platforms).
Aggregated View of Studies
To look for patterns across the three studies (current financial study, CUE, and Tom’s two studies) I aggregated the data by metrics and for unmoderated and moderated methods in Tables 2, 3, and 4. The differences are displayed as unmoderated minus moderated (so positive values indicate scores were higher in unmoderated).
| Study | MAD% | Diff% | Correlation |
|---|---|---|---|
| MW | 17% | -1.0% | 0.29 |
| Desktop | 14% | -6.0% | 0.35 |
| App | 13% | -1.0% | 0.18 |
| CUE | 7% | -1.0% | 0.24 |
| Tullis 1 | 15% | 4.0% | 0.70 |
| Tullis 2 | 8% | -0.2% | 0.98 |
| Mean | 12% | -1% | 0.61 |
Table 2: Differences in completion rates across the six data sources show a MAD of 12%, mean difference of -1%, and correlation of r = .61 (Fisher Transformed).
| Study | MAD% | Diff% | Correlation |
|---|---|---|---|
| MW | 84% | 77.0% | 0.78 |
| Desktop | 32% | 65.7% | 0.70 |
| App | 44% | 37.0% | 0.71 |
| CUE | 31% | -28.0% | 0.88 |
| Tullis 1 | 28% | 12.0% | 0.65 |
| Tullis 2 | 19% | 4.0% | 0.94 |
| Mean | 40% | 28% | 0.81 |
Table 3: Differences in task times across the six data sources show a MAD of 40%, mean difference of 28%, and correlation of r = .81 (Fisher Transformed).
| Study | MAD% | Diff% | Correlation |
|---|---|---|---|
| MW | 8% | 1.0% | 0.88 |
| Desktop | 6% | -5.4% | 0.66 |
| App | 8% | 2% | 0.05 |
| CUE | 2% | 2.0% | -- |
| Tullis 1 | 18% | -17.0% | 0.49 |
| Tullis 2 | 21% | 13.0% | 0.04 |
| Mean | 11% | -1% | 0.51 |
Table 4: Differences in ease (post-task or post-study) across the six data sources show a MAD % of 11%, mean difference of -1%, and correlation of r = .51 (Fisher Transformed).
Tables 2 shows that completion rates had relatively good agreement between methods, with a MAD of 12% and the raw difference of -1% (slightly lower completion rates for unmoderated).
Table 3 shows that task time differed more substantially across the studies with a MAD of 40%, showing that unmoderated task times generally took about 28% longer on average than their moderated counterparts. This longer task time in unmoderated studies is also consistent with Andreasen et al., 2007), which found unmoderated participants spent nearly three times as long on the study (63 minutes vs. 23 minutes compared to lab participants).
Table 4 shows stronger agreement for post-task/post-study ease questions with a MAD of 11% and a raw difference of -1%, the same as the completion rate (slightly lower for unmoderated). The subjective data from Tullis shows larger differences, possibly because they used items from a questionnaire with unknown reliability.
Summary & Discussion
Across the three studies with multiple tasks and metrics I found:
Task completion and task ease are very similar. There were only modest differences for completion rates (MAD 12%) and post-task (e.g. SEQ) or post-study subjective ease questions (e.g. SUS) (MAD 11%). This encouraging result suggests task-completion and perceived ease may only differ by a modest amount between methods and may be more interchangeable estimates (especially considering the small sample sizes used in the lab studies).
Task time differs more substantially. The average difference in tasks time was 28% and a MAD of 40%. In some cases, task times can take more than twice as long depending on the method. This metric seems less comparable across methods versus completion rates and perceived ease. Which time is the “right” time is worthy of its own investigation.
Task times are longer in unmoderated: Despite possible influences from a moderator and thinking aloud, unmoderated task times (successfully and unsuccessfully attempts) tend to take longer. We suspect it’s most likely because unmoderated participants are interrupted or take breaks during tasks, which, even after removing large outliers, still inflates the times. In the lab, participants are being directly observed, which likely limits straying from the task and keeps task times lower.
Correlations may mask differences or make differences seem larger. While correlations are a common method for assessing agreement, they don’t provide an idea of the magnitude of the differences. What’s more, small differences that show good correspondence may have low to no correlation because the values fall within too narrow a range.
Small lab studies may exaggerate differences. All lab studies in this analysis used between 8 and 12 participants. While this is typical for a lab study, the variability in the metrics due to sampling error means the averages will fluctuate much more than in larger sample studies. The meta-analytic approach taken here allows us to look at patterns with more participants. Future research can examine lab-based studies with larger sample sizes to minimize this influence.
Use validated questionnaires. Tullis et al. found the least amount of agreement with their questionnaire data. Their differences were three to five times as large as the other data sets. A possible reason is that in our data we used validated questionnaires (SEQ and SUS), whereas they compared single items with unknown psychometric properties.