When done well, surveys are an excellent method for collecting data quickly from a geographically diverse population of users, customers, or prospects.
When done well, surveys are an excellent method for collecting data quickly from a geographically diverse population of users, customers, or prospects.
In an earlier article, I described 15 types of the most common rating scale items and when you might use them. While rating scales are an important part of a survey, they aren’t the only part. Another key ingredient to a successful survey is knowing which type of question to use.
While there isn’t an official book of survey questions or survey taxonomy, I find it helpful to break down survey questions into four classes: open-ended, closed-ended (static), closed-ended (dynamic), and task-based. I refer to these loosely as questions or more generally as items because they are often only statements for people to respond to or even instruction for participants to follow. While they might not all be questions, they are asking people to do or type something. Figure 1 below shows a visual breakdown of the different question/item types.
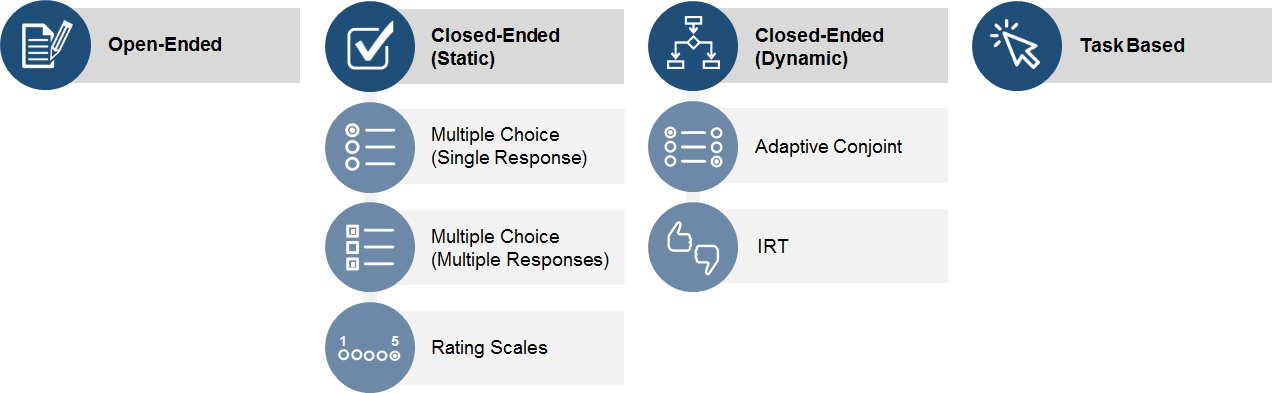
Figure 1: Taxonomy of survey question classes.
Here are more details on these classes of questions and some guidance on when and why to use them.
1. Open-Ended
If you could individually interview each survey respondent, you’d probably ask a lot of open-ended questions. For electronic surveys, open-ended items allow participants to articulate their thoughts in their own words (from one word to many sentences). Responses can be examined and coded into variables and analyzed statistically. Some examples of open-ended items from different types of surveys include:
- What one thing would you improve on the website?
- What three words do you associate with the brand?
- Briefly describe why the task was difficult to complete.
- Please describe why you gave the rating you did.
- In your own words, how would you describe this product to a friend?
Open-ended questions are usually difficult to analyze because the responses are more variable. They’re also harder for people to respond to (especially when typing on small mobile screens). If you have a finite set of options, closed-ended responses may be the better option or consider a hybrid: a closed-ended question with an “Other” option (see below).
2. Closed-Ended (Static)
Whereas open-ended questions/items allow for any free response, closed-ended questions—as the name suggest—enumerate the options for participants to select from. These are generally classified into three types: multiple choice with a single response, multiple choice with multiple responses, or rating scales. These types are considered static because respondents see all the same combinations and questions (even if they’re presented in random order), in contrast to closed-ended dynamic questions, which are presented in the next section.
a. Multiple Choice (Single Response)
The most familiar—and likely most used item in a survey—is a multiple-choice option with a single response. These types are typical for most demographic questions such as age, gender, education, and income. Be sure options for this question are really mutually exclusive. If participants can select more than one answer, use the multiple response type. Options can be displayed as radio buttons, as shown in the figure, or drop-down lists.
 In general, you should plan to randomize the order of the choices unless they have a natural sequence (like the education question above). Randomized responses minimize the subtle biases respondents have (such as selecting the first choice in a list).
In general, you should plan to randomize the order of the choices unless they have a natural sequence (like the education question above). Randomized responses minimize the subtle biases respondents have (such as selecting the first choice in a list).
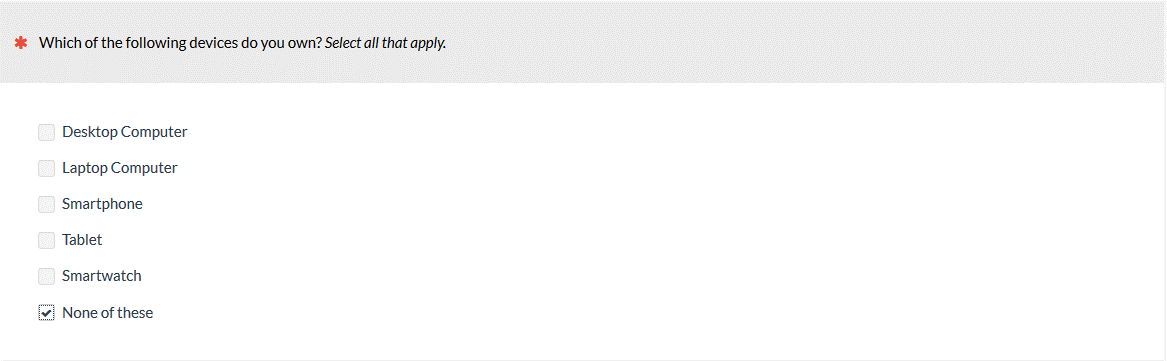
b. Multiple Choice (Multiple Responses)
The multiple-choice question with multiple response type is similarly common and works when multiple values are expected, such as asking participants what electronic devices they own or brands participants are familiar with (example below).
You can often get the best of both worlds by adding an “Other” option to a closed-ended question as in the example below which asks participants to recall what they may have used the Cigna mobile app for (this data appears in the Health Insurance Benchmark):
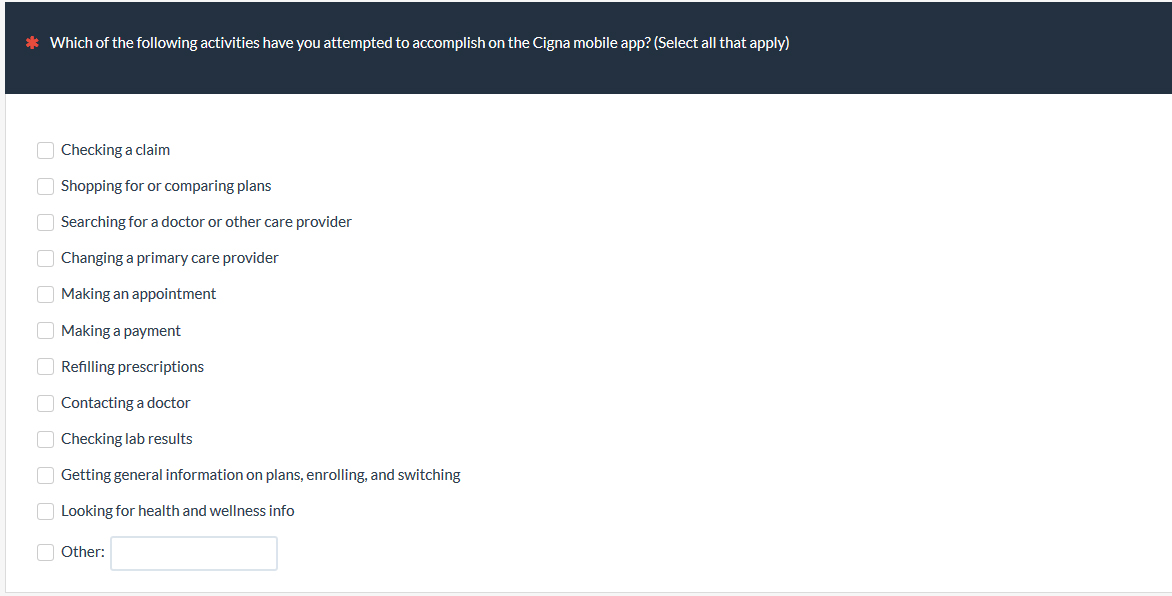 Like the single-response variation, unless there is an expected order to the choices, randomize their presentation order using survey software like MUIQ to minimize response biases (and leave the “Other” at the bottom).
Like the single-response variation, unless there is an expected order to the choices, randomize their presentation order using survey software like MUIQ to minimize response biases (and leave the “Other” at the bottom).
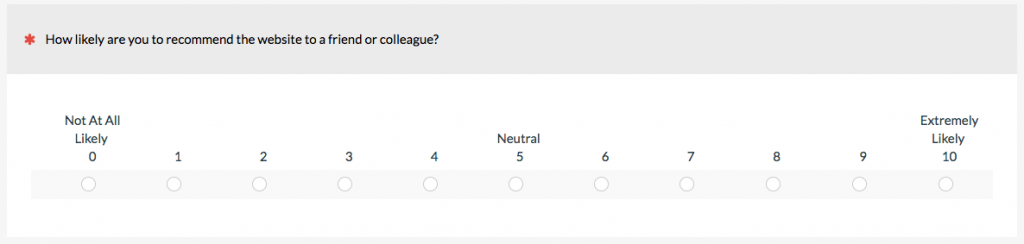
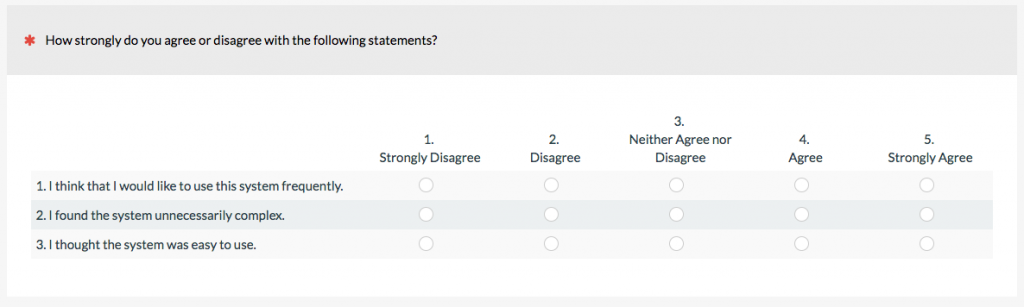
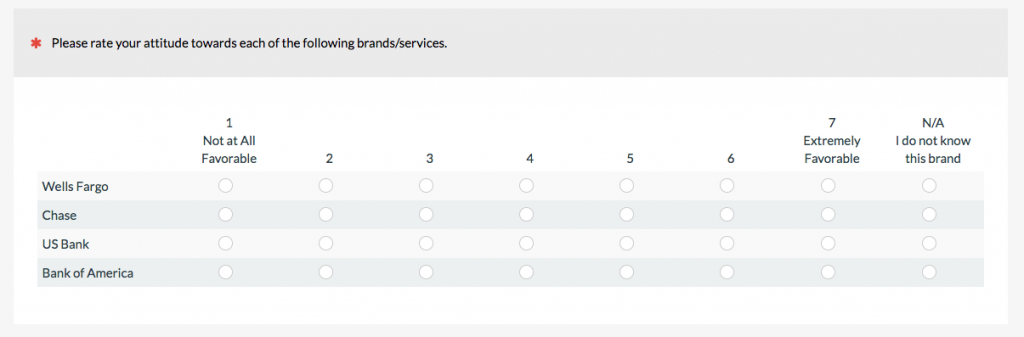
c. Rating Scales
Rating scales are a special type of closed-ended question that usually involve asking participants to rate abstract concepts, such as satisfaction, ease, or likelihood to recommend. The item selection can have a big impact on both the responses and interpretation.
There are different ways of classifying rating scales and slight variations can result in different looking rating scales, even though they’re just variations on the same scale. In an earlier article, I described 15 of them, with the most common scales being linear numeric, Likert, and frequency.
3. Closed-Ended (Dynamic)
There essentially isn’t much difference for a respondent who completes the older paper and pencil surveys versus the newer electronically administered ones. One major difference with digital surveys that’s less known is the ability to change which items and response options participants receive, based on their prior choices. This dynamic presentation uses the same rating scales and multiple-choice questions but the question order and choices change using adaptive logic (numerical algorithms programmed in the software). The two most common forms of dynamic questioning are adaptive conjoint analysis and item response theory (IRT).
a. Adaptive Conjoint Analysis/ MaxDiff
Adaptive conjoint is most commonly used to identify what features or attributes of a product or experience are most important. Respondents are presented with combinations of features and asked to rate their preference or interest. The software then presents the optimal combination to identify the best combinations and understand the relative importance or “utility” of each feature. A MaxDiff study is one type of adaptive conjoint where participants are presented subsets of features or items and asked to select the most and least important attributes. The example below comes from a MaxDiff study of online hotel websites.
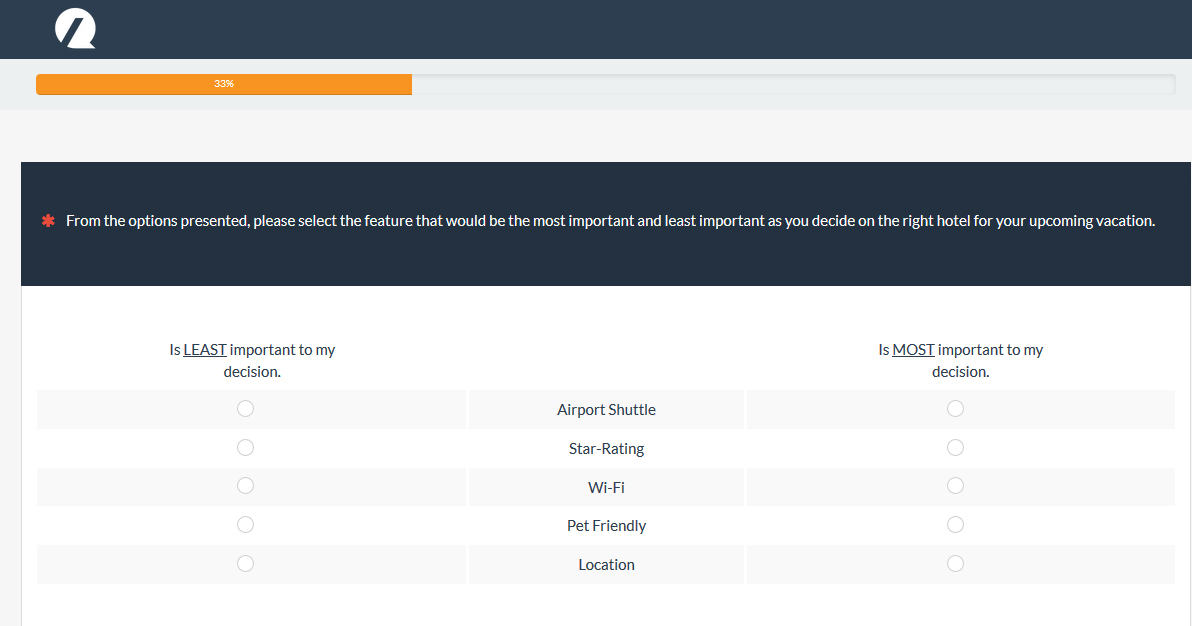
In general, the more features that you need to assess importance, the more combinations of questions need to be presented to the participants.
b. Item Response Theory
Item response theory (IRT) also presents participants with items they can agree to (using yes/no questions—dichotomous modeling) or multiple-choice rating scales (polytomous modeling). The biggest advantage of IRT is that it can estimate the underlying attribute (such as mastery of a concept, perception of ease, satisfaction, and UX quality) more accurately and with fewer items than traditional static presentations. It is also usually administered using an adaptive algorithm.
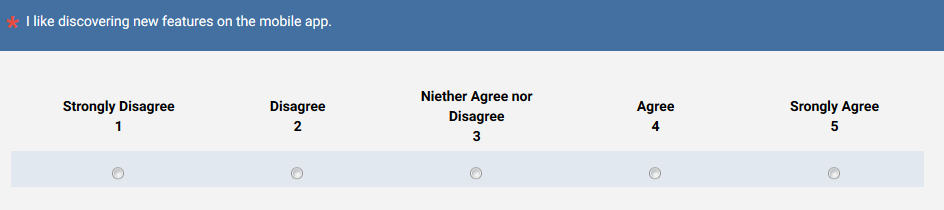
The most common application of IRT is in achievement tests, such as the GRE, which adapts question difficulty to correct or incorrect responses. In UX research, the SUPR-Qm is presented dynamically to participants to evaluate the quality of a mobile app experience. The more a respondent agrees (4s and 5s) to items, the more difficult subsequent items are presented. While the SUPR-Qm has 16 calibrated items, on average, respondents will only need to answer 4 or 5 items to achieve a reliable estimate of their attitude; a benefit of the dynamic presentation. An example item from the SUPR-Qm is shown below. While most respondents won’t realize their questions are adapted to their responses (they look like just another Likert item), your respondents will thank you for the fewer items!
4. Task/Activity Based
An unmoderated usability test can be viewed as a special type of electronic survey with task-based questions. Instead of relying on a self-reported response, a task/activity-based question asks participants to attempt to do something, usually on a website, prototype, or hosted image.
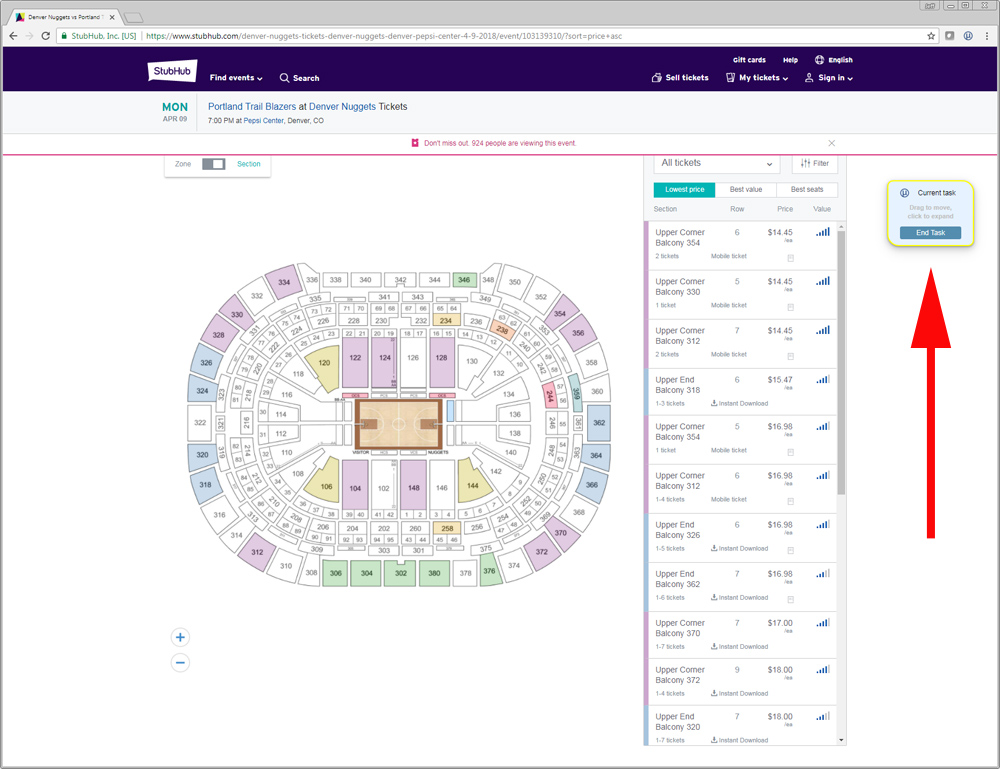
Software, like our MUIQ platform, presents respondents with a task (e.g. Find the local branch) in a floating or fixed window (see below). The software records where users click, how long they take, and can even “time-out” so it only presents screens for a few seconds.

Tree tests are variations on task-based questions, which have participants navigate through the labels and menus (called the taxonomy) of a website or software app.
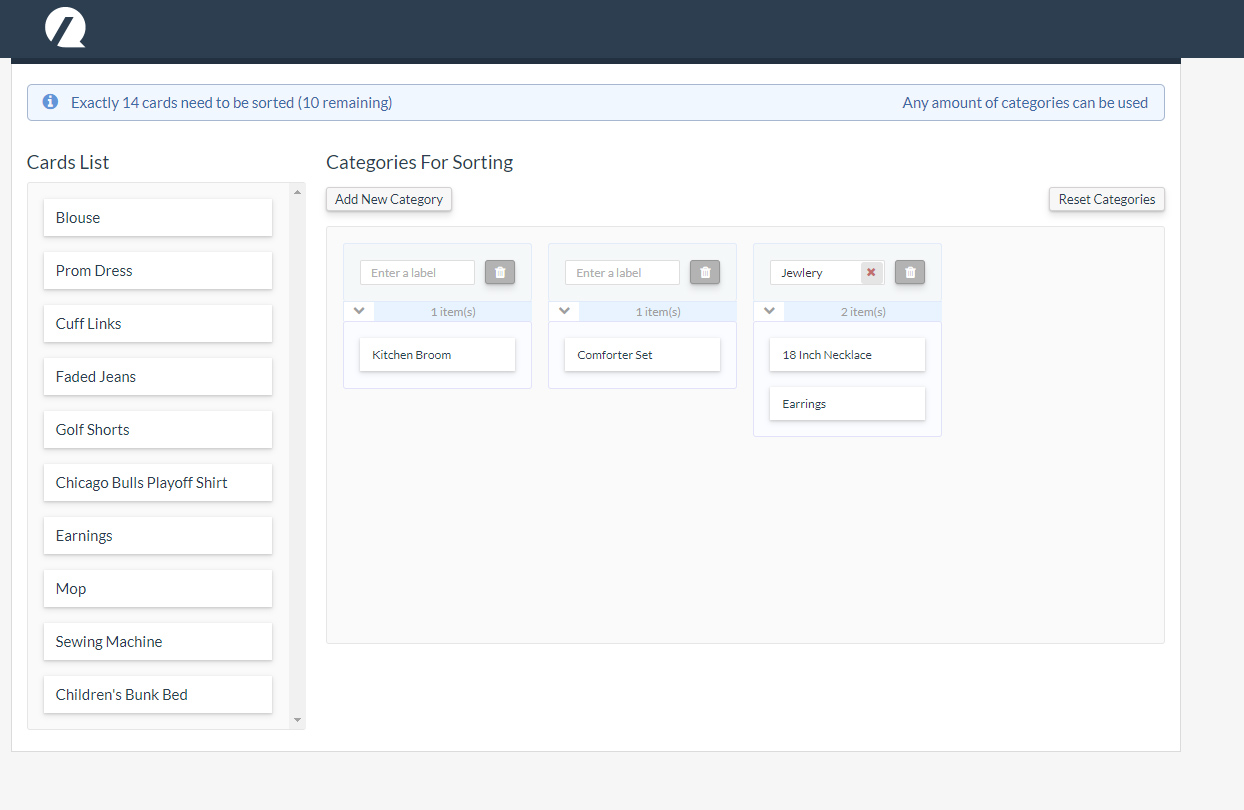
A card sorting question asks participants to sort items (products, content, features) into categories. Researchers can then understand which items cluster together and which names respondents use to categorize things. The figure below shows examples of what the respondent sees in a card sort and one of the outputs (a dendrogram).