 The Single Ease Question (SEQ®) is a single seven-point item that measures the perceived ease of task completion. It is commonly used in usability testing.
The Single Ease Question (SEQ®) is a single seven-point item that measures the perceived ease of task completion. It is commonly used in usability testing.
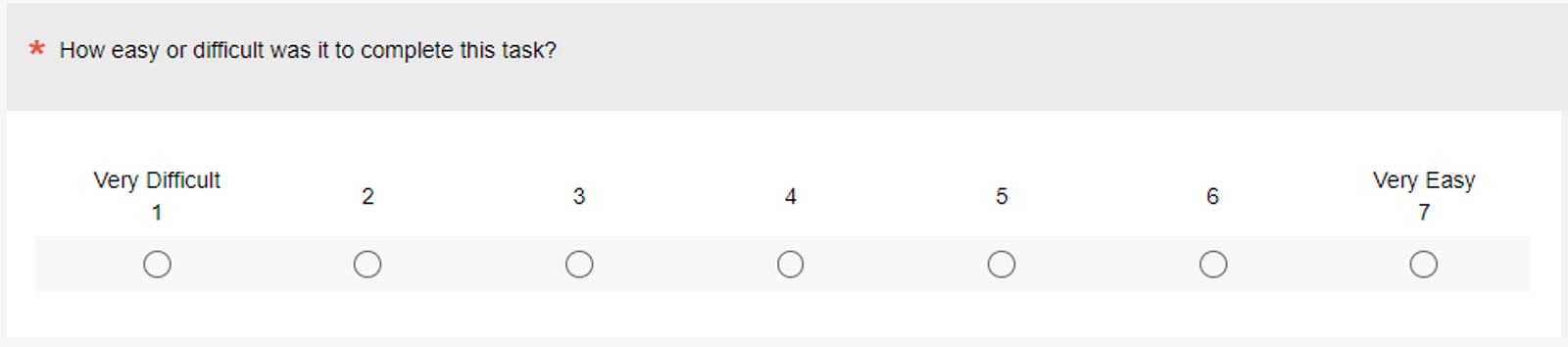
Since its introduction in 2009 [PDF], some researchers have made variations in its design. Figure 1 shows the version that we currently use.
In 2022, we decided to test some of the other SEQ variants we had used in the past or seen in the UX literature to help us decide if we should continue using our current version. The three variations each change one of the following elements of the scale:
- Polarity of scale endpoints
- Wording of the item stem
- Presence or absence of numbers on response options
In this article, we summarize the findings and takeaways from these three experiments.
The Three Experiments
In all three experiments, we used our MUIQ® platform to conduct unmoderated remote UX studies with a Greco-Latin experimental design to compare standard and alternate versions of the SEQ in the contexts of attempting easy and hard tasks. As a reminder, a Greco-Latin square design combines the best of within-subjects and between-subjects experimental designs. For example, within-subjects analyses are more sensitive to detection of statistically significant effects and allow for assessment of preference, while between-subjects analyses are immune to the possibility of asymmetric transfer.
The easy and hard tasks were
- Easy task: Find a blender on the Amazon website for under $50. Copy or remember the name of the blender brand.
- Hard task: Please find out how much the monthly cost of an iPhone 12 with 64GB of storage with service for one line is on the AT&T website. Copy or remember the monthly cost (including all fees).
This experimental design had three independent variables: item format (standard or alternate), rating context (easy or hard task), and order of presentation (standard/easy then alternate/hard; standard/hard then alternate/easy; alternate/easy then standard/hard; alternate/hard then standard/easy).
After attempting each task, participants completed either the standard or alternate version of the SEQ in accordance with the experimental design. At the end, the participants indicated which SEQ version they preferred.
Experiment 1: Endpoint Polarity
In our first experiment, we wanted to know whether changing the scale polarity from Easy→Difficult to Difficult→Easy changes scores.
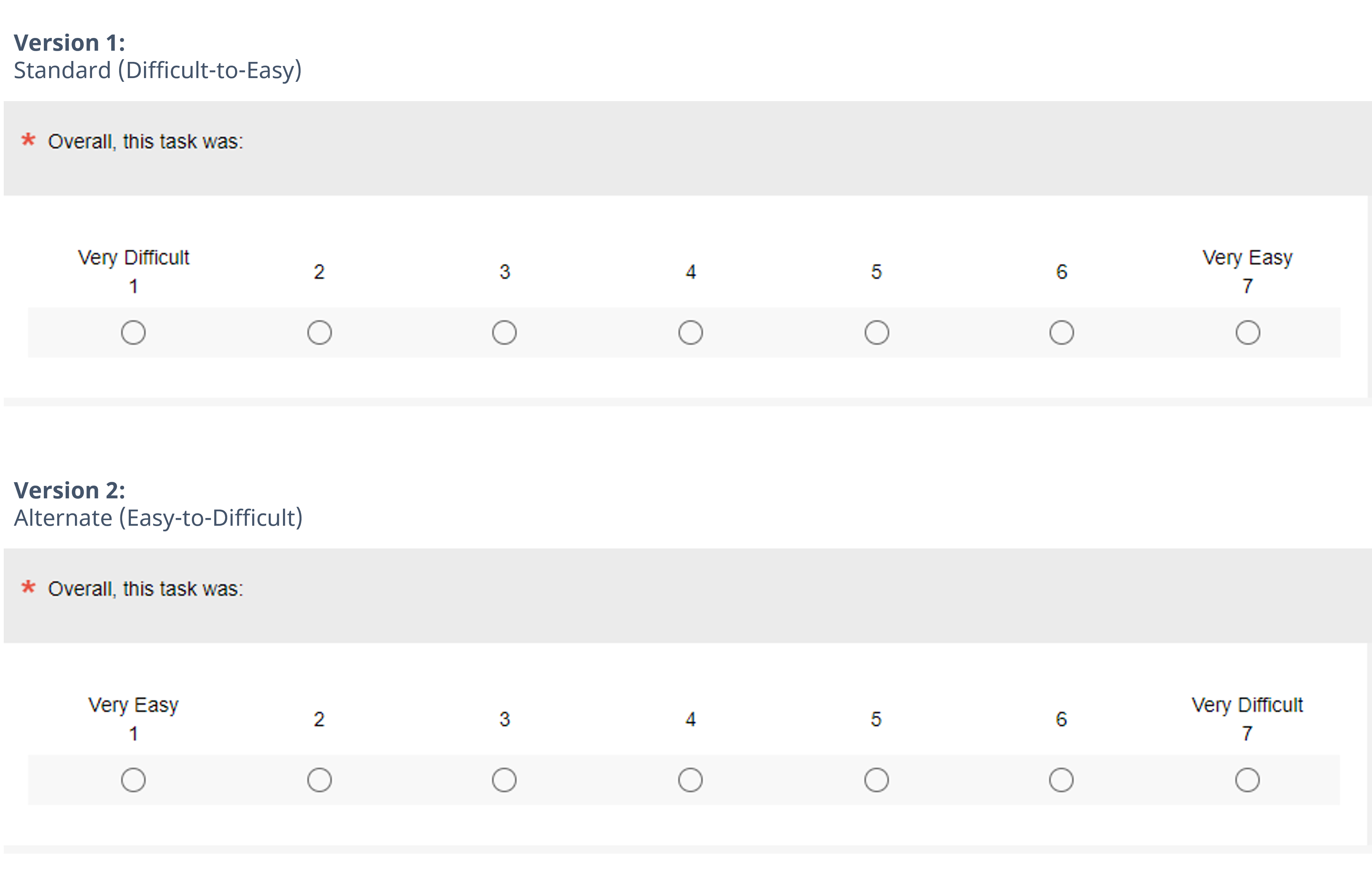
We manipulated endpoint polarity, using versions that varied whether the endpoints were “Very Difficult” on the left and “Very Easy” on the right (as in the 2006 Tedesco and Tullis study [PDF]) or the reverse (as in the 2009 Sauro and Dumas study).
Figure 2 shows the two versions used in this experiment. Using the Greco-Latin experimental design described earlier, we varied these item formats and the difficulty of the tasks that the participants attempted. We used this data to see whether there was evidence for
- A left-side bias (are means inflated when “Very Easy” is on the left?)
- Difference in means
- Difference in top-box scores
We found
- No evidence of a left-side bias. When “Very Easy” was on the left, the means were not statistically different.
- Overall, no significant difference in top-box scores, but there was an interaction between item format and task difficulty such that the difference in top-box scores was statistically significant, but only for the difficult task.
- 53% of respondents had no preference for a version, while among those who had a preference, it was significantly stronger for the standard version (29%) than for the alternate (18%).
Experiment 2: Item Stem
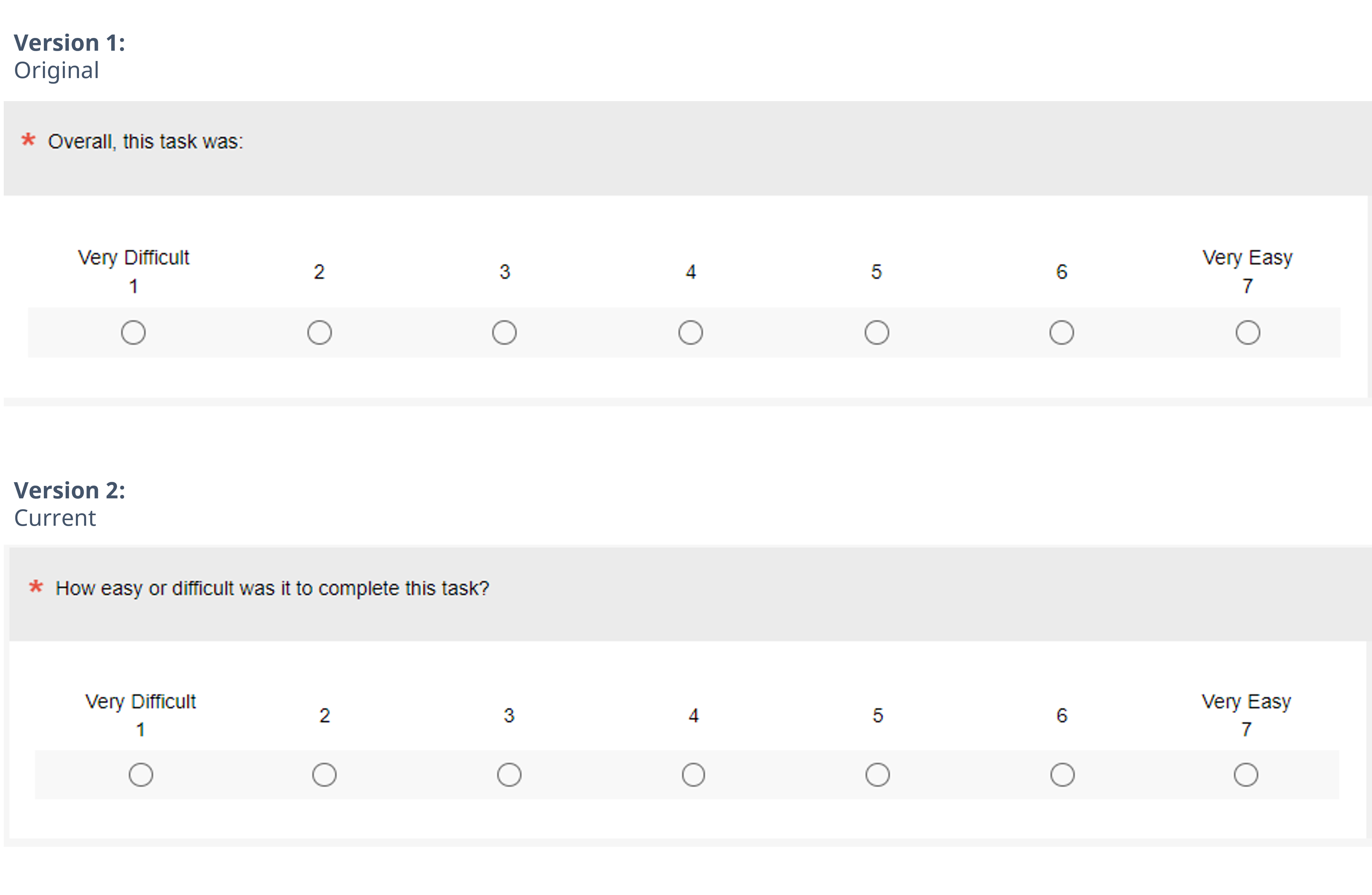
Our second experiment used the same experimental design as the first, but the manipulation was just to the wording of the item stem. Specifically, as shown in Figure 3, we compared the original stem (“Overall this task was:”) with our current version (“How easy or difficult was it to complete this task?”).
Across many ways of analyzing the data (means and top-box scores), we found no statistically significant differences (in fact, the smallest p-value across the analyses was .30). For those who had a preference, it was about evenly split between the versions, with 55% having no preference.
Experiment 3: Response Option Numbering
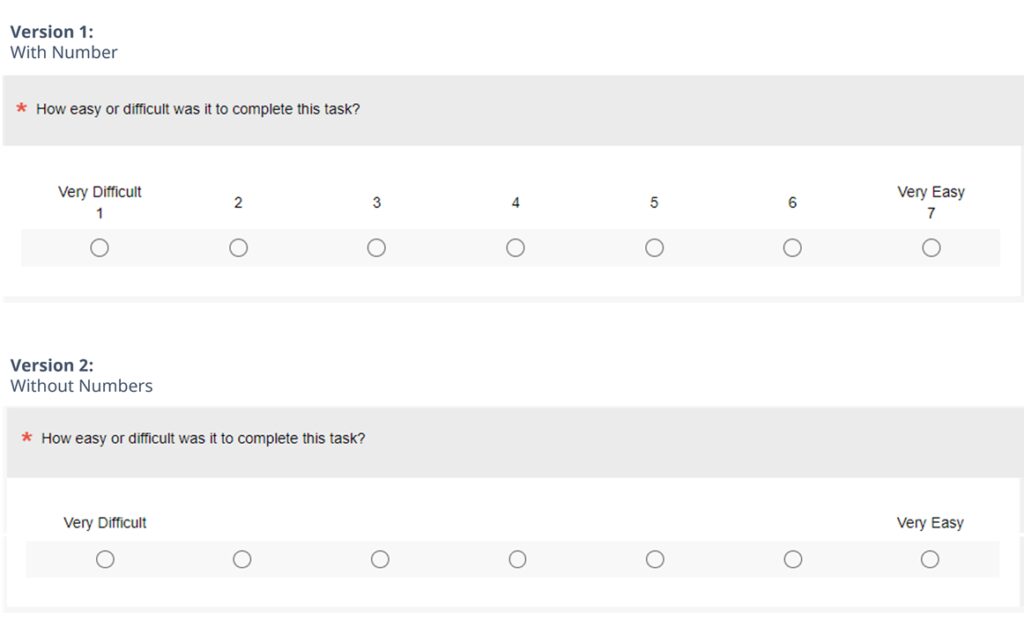
Our third experiment used the same experimental design as the other two, but the manipulation was just to the presence or absence of numbers as response option labels. As shown in Figure 4, we compared our current numbered version with an otherwise identical unnumbered version.
Across a broad suite of analyses of means and top-box scores, we found no statistically significant differences, although some top-box differences were large enough to be concerning. The version with numbers appears to have the potential for better discrimination between easy and hard tasks, and among those who had a preference, the preference for the numbered version was statistically significant and just over 2:1.
Item Variation Takeaways
These analyses (and other considerations) support the continued use of our current version (Figure 1).
Endpoint polarity: Any concerns we had about differences in endpoint polarity on our historical SEQ means were alleviated by the results of the first experiment. We found significant differences in top-box scores for the hard task but no significant differences in means, which is what we usually analyze and report. We prefer our current polarity because we know from experience that it is easier to discuss results with stakeholders when larger numbers indicate a better outcome, and those who had a preference significantly preferred the current polarity. It’s reassuring to know that data from either format are likely comparable.
Item stem wording: Any concerns we had about the potential influence of item stem wording on response selections were addressed by the item stem experiment. There was no evidence that mentioning “easy” first in the stem produced different measurements than the bare-bones stem (“Overall, this was:”). This suggests either wording will generate near identical results.
Numeric labels: Providing numeric labels for response options is the more commonly used format, has the potential for better discrimination between easy and hard tasks (when using top-box scores) and was significantly preferred over the version without numbers. We recommend keeping numbers in.
")

