 Rating scales have been around for close to a century.
It’s no wonder there are many questions about best practices and pitfalls to avoid. And like any topic that’s been around for that long, there are urban legends, partial truths, context-dependent findings, and just plain misconceptions about the “right” and “wrong” way to use and interpret rating scales.
We’ve been researching and conducting our own studies to clarify the issue using data that’s relevant to UX researchers. This article summarizes the eight topics covered in the MeasuringU webinar we presented in September 2020 with some updates from recent additional studies we’ve conducted.
Rating scales have been around for close to a century.
It’s no wonder there are many questions about best practices and pitfalls to avoid. And like any topic that’s been around for that long, there are urban legends, partial truths, context-dependent findings, and just plain misconceptions about the “right” and “wrong” way to use and interpret rating scales.
We’ve been researching and conducting our own studies to clarify the issue using data that’s relevant to UX researchers. This article summarizes the eight topics covered in the MeasuringU webinar we presented in September 2020 with some updates from recent additional studies we’ve conducted.
1. Is there a left-side bias for rating scales?
Consider the two versions of the following Likert-type item (Figure 1). The only difference is the orientation of the response labels. In the top example, Extremely Disagree is on the left side, and in the bottom example, Extremely Disagree is on the right side. Are respondents more inclined to select the option presented on the far left side? After all, in western languages we read from left to right, suggesting the possibility of a primacy effect.
Figure 1: Two orientations of response labels in agreement items.
Out of six studies we reviewed, four reported credible effect sizes for a bias. Three of those were consistent with a left-side bias and one was consistent with a right-side bias. The average estimate of the left-side bias across those studies was about half a percent. The other two papers we reviewed reported much stronger left-side biases but failed to properly counterbalance their experimental conditions, making their results uninterpretable. Takeaway: There may be a small left-side bias, but it hasn’t been definitely proven, especially because of the confounding experimental designs we found in two studies that claimed a large left-side bias.2. Are agreement items more prone to acquiescence?
Agreement scales, including the Likert example in Figure 1, are one of the most common ways to assess people’s attitude toward a sentiment (convenient, familiar to respondents). An alternative option is to phrase items specifically about what you want respondents to consider. Figure 2 shows an example of the two items from the UMUX-Lite. The top part of Figure 2 shows the items phrased as agree-disagree items on a seven-point scale. The bottom part has the items worded for each item specifically. Both cover the same concepts: capability of meeting requirements and ease of use. There are recommendations in the literature to use item-specific endpoints based on claims that agree/disagree scales elicit higher rates of agreement.
Figure 2: Examples of agreement and item-specific versions of the UMUX-Lite.
Jim conducted a study to find out whether there was evidence for this in UX metrics. In his study, 200 participants (IBM employees) rated their most recent experience with their auto insurance website. Participants were randomly assigned to either an item-specific or agreement version of the UMUX-Lite (Figure 2). The mean across 14 UX measures for the agreement format was 0.5% higher than the item specific mean, but this modest difference wasn’t statistically significant. Takeaway: There is no compelling evidence we’ve seen that suggests agreement scales are more affected by acquiescence bias than matching item-specific scales.3. Do more extreme endpoints affect ratings?
Labels on rating scales can affect responses, from full versus partial labeling, neutral points, and the words used in the labels. How does using stronger language on the endpoints affect responses? Are people less willing to agree to more extreme statements, and if so, does that impact scores? To find out, we conducted a within-subjects study with 213 participants who reflected on a recent retail purchase and completed two versions of a five-point satisfaction scale. The only difference in the scales was using “Extremely” instead of “Very” (Figure 3).
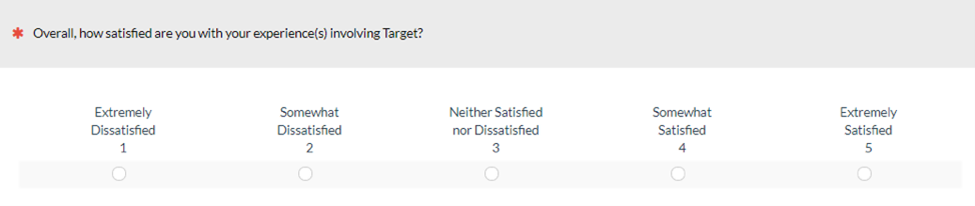
Figure 3: “Very” and “Extremely” versions of a five-point satisfaction scale.
We found some evidence that people might be less likely to agree to scales when “Extremely” was used; however, the difference was a small 0.3% and not statistically significant. Takeaway: Satisfaction scores were slightly higher for “Very” vs. “Extremely” used in endpoint labels, but the difference was not significant.4. Does using grids affect scores?
Combining rating scales into grids allows for a more compact presentation of multiple items that have the same response options. The published literature on grids suggests they allow faster completion times and have higher reliability. There is also evidence, however, that grids result in far more inattentive “straightlining” by participants and slightly higher drop-out rates. Also, people don’t seem to like large grids.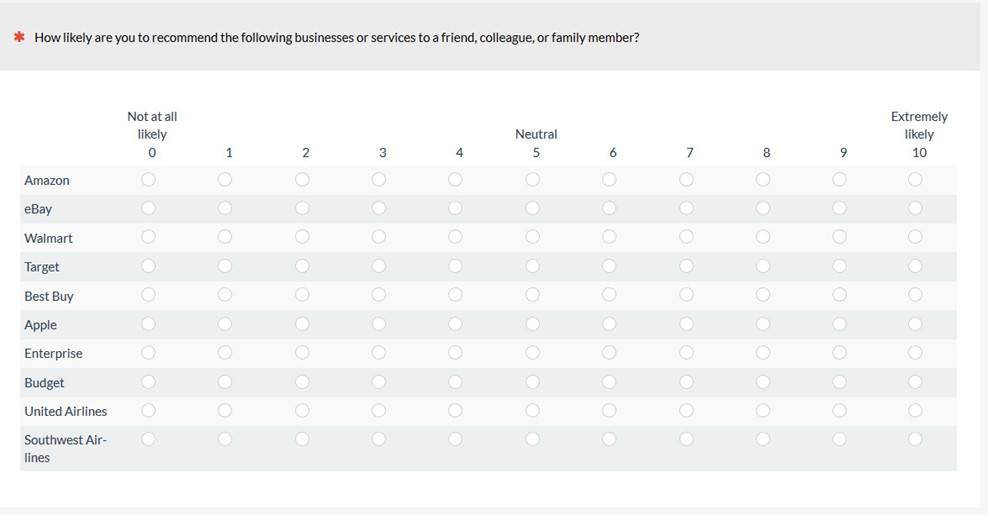
Figure 4: Example of a rating scale grid.
To find out how grids affect responses, we had 399 participants rate how likely they were to recommend ten consumer brands using an eleven-point Likelihood-to-Recommend (LTR) item—the same one used to compute the Net Promoter Score. Participants randomly received a survey presenting the items either in a grid or separately (Figure 4). The means of eight out of the ten brands were slightly lower when presented in a grid versus alone. The overall difference, however, was relatively small (1.5%) and not statistically significant (Figure 5).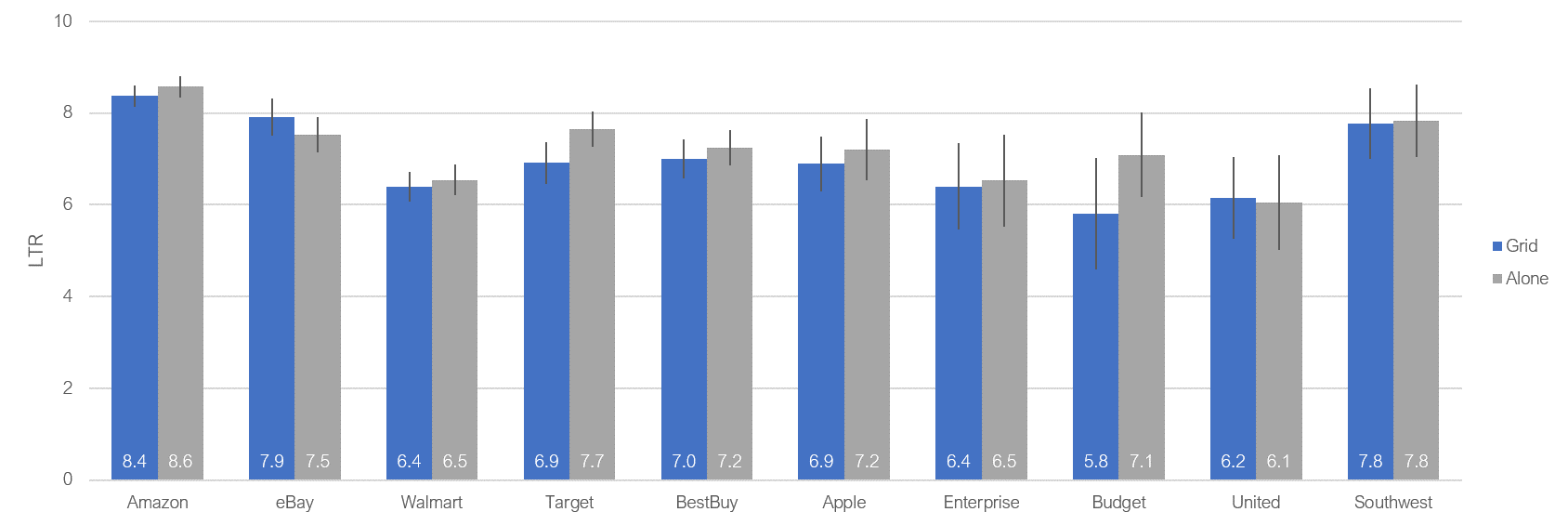
Figure 5: LTR for ten retail brands collected with grids or with a series of individual items.
Takeaway: Grids may have a small effect of lowering the means compared to presenting the items alone, this difference was not statistically significant, and participants actually prefer answering in smaller grids (fewer than ~20 items).5. Are face emojis better than numeric scales?
What does a “4” really mean on a five-point scale? Do respondents really interpret numeric scales correctly, or would something like a facial expression or emoji provide more reliable results (Figure 6)? Face emojis may be easier to understand than numbers, but do they elicit different responses compared to standard numeric scales? There are multiple face scales in use (some standardized and copyrighted), and some research suggests they’re popular with children and easier to understand than numeric scales. Other research has questioned whether face emojis are interpreted in the same way across cultures.
Figure 6: Face emoji version of the UMUX-Lite.
To determine whether faces are more valid, we first needed to see whether they elicit a different response from participants than standard numeric items. We conducted a study in MUIQ with 240 participants who rated their experience with streaming media services (e.g. Netflix, Hulu) using the UMUX-Lite. In the experimental design of this study, participants saw both versions of the scale (faces and numeric) in counterbalanced order (the study used a balanced Greco-Latin square design). We found face emojis had slightly lower means—half a point (0.5%)—on the 101-point UMUX-Lite scale (response distributions were also comparable). Takeaway: We found slightly lower means (less agreement) when using face emojis compared to standard numeric scales, but the difference was not statistically significant.6. Are sliders better than standard scales?
Visual analog scales (VAS), more often just referred to as slider scales, allow respondents to select a wider range of values than allowed by conventional discrete response options. Originally these were presented on paper and respondents would draw a line to indicate their response. Now most sliders are digital. There is some evidence that continuous response options provide more sensitivity than traditional multi-point scales, especially over those with fewer points. In an earlier analysis, we found a VAS version of the Subjective Mental Effort Questionnaire (SMEQ) to be modestly more sensitive (detecting more statistical differences between products at smaller sample sizes) than a seven-point version of the SEQ. However, the slider used in that study (the SMEQ) also had different (and calibrated) labels, and it ranged from 0 to 150. The advantage observed might not generalize to standard sliders with just endpoints labeled and a range from 0 to 100. We conducted two more studies to provide additional data. We had 180 participants rate their experience on streaming entertainment websites (e.g., Netflix, Hulu, Disney+). Participants completed both a standard five-point version of the UMUX-Lite and a slider version (Figure 7), with presentation order and rating contexts counterbalanced with a Greco-Latin square design.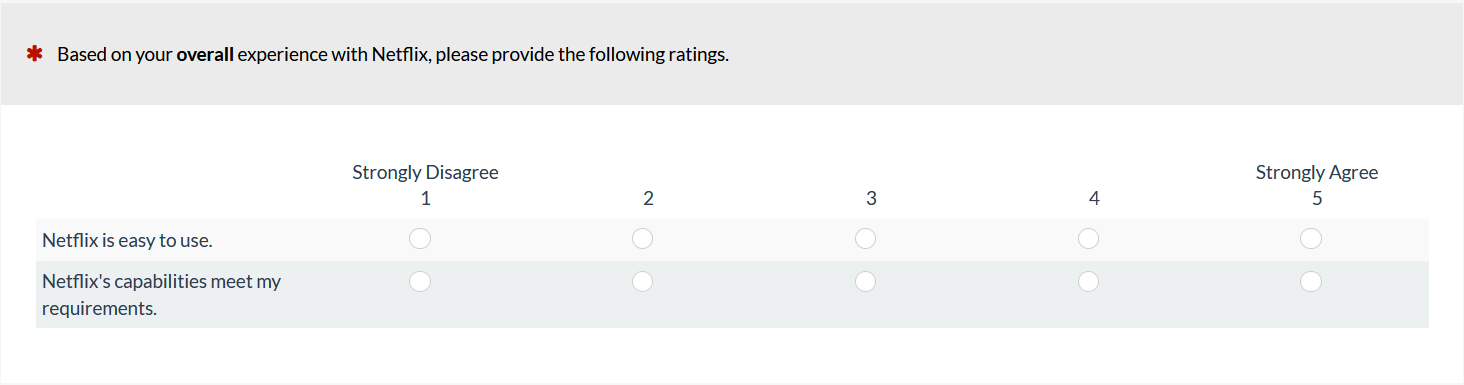
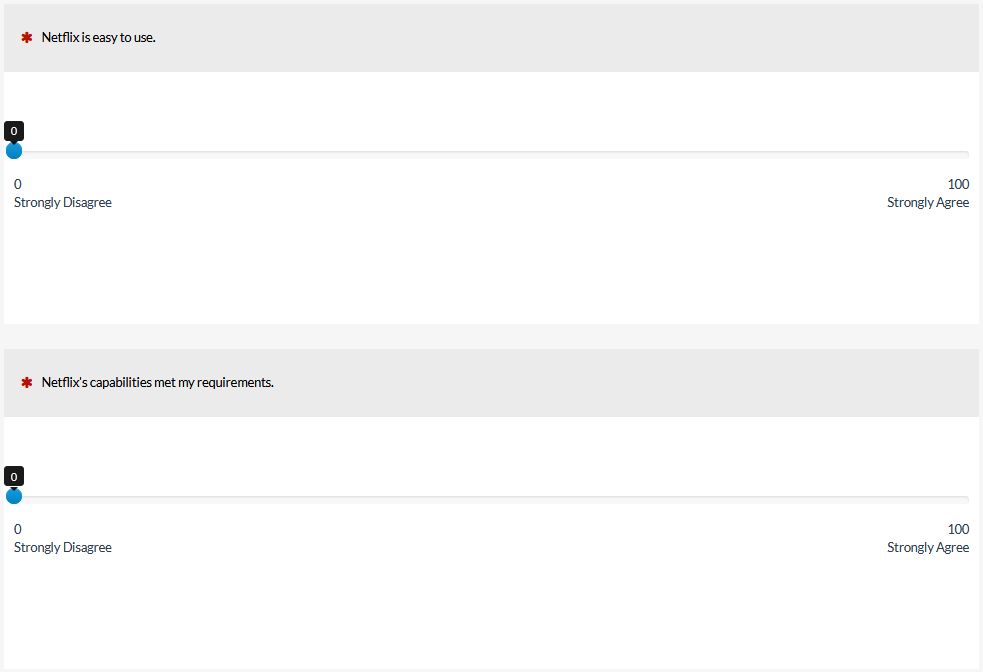
Figure 7: Numeric and slider versions of the UMUX-Lite.
We found slightly higher mean scores when sliders were used (more agreement), but as is common with item format manipulations, this difference was small (0.6%) and not statistically significant (response distributions were also comparable). We then conducted additional Monte Carlo analyses to assess the relative sensitivities of these numeric and slider scales, finding a modest advantage for sliders and corroborating the earlier study on the SMEQ. Keep in mind that the drawback of sliders is that they tend to take longer for participants to complete, may be harder to respond to for some populations, and may increase non-response rates. Takeaway: Sliders may provide more sensitivity than standard multi-point scales, especially over those with fewer points (≤ 5), but may be harder for respondents to use and may increase non-response rates.7. Are star scales better than standard scales?
Whether you’re rating a product on Amazon, a dining experience on Yelp, or a mobile app in the App or Play Store, you can see that the five-star rating system is ubiquitous. Does the familiarity of stars offer a better rating system than traditional numbered scales? To see whether using stars generated different scores than standard scales, we had 155 participants rate their experience with a streaming service (e.g., Hulu, Netflix) using the standard five-point numeric version of the UMUX-Lite and a five-star version (Figure 8). The presentation order and rating contexts were counterbalanced using a Greco-Latin square design.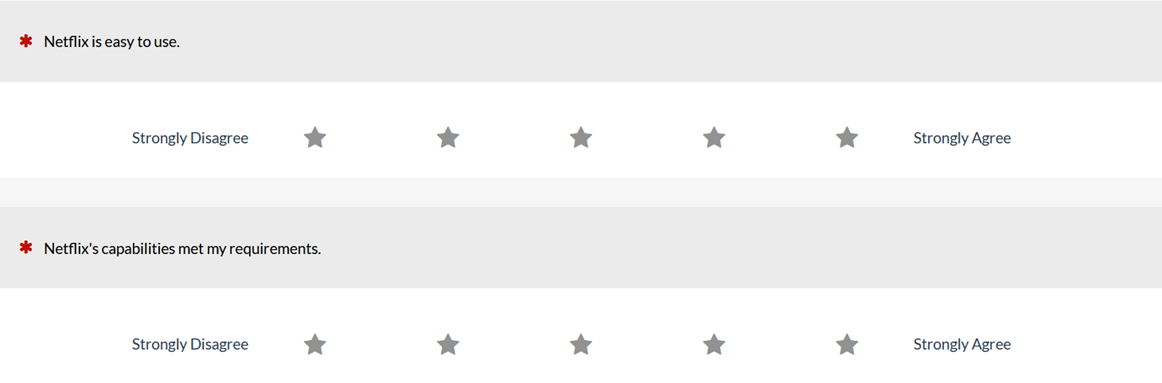
Figure 8: Standard numeric and star versions of the UMUX-Lite.
We found slightly higher mean scores for the stars (1.3%), but the difference was not statistically significant (and response distributions were comparable). There was a slight but significant effect of the order of presentation, with a larger mean for star scales when stars came after numeric scales. Takeaway: We found little difference between responses using stars and numeric scales. Researchers can comfortably use stars but should avoid mixing them with numeric scales in the same study.8. Should scales include negative numbers?
Rating scales are typically labeled with positive integers and sometimes include 0 (e.g., 1 to 5, 1 to 7, or 0 to 10). But some use negative numbers on scales (e.g., -2 to +2, -3 to +3, or -5 to +5), especially when one endpoint has a negative tone (e.g., strongly disagree). The published literature includes research that found participants had no problem using negative numbers when rating a system or experience [PDF] but were more hesitant using negative numbers to rate themselves [PDF]. To understand the impact of negative numbers, we had 256 participants rate their recent experience with a streaming service (e.g., Netflix, Hulu). They completed both the standard positively numbered UMUX-Lite and one scale numbered -2 to 2 (Figure 9). Rating contexts and presentation order were counterbalanced with a Greco-Latin square design.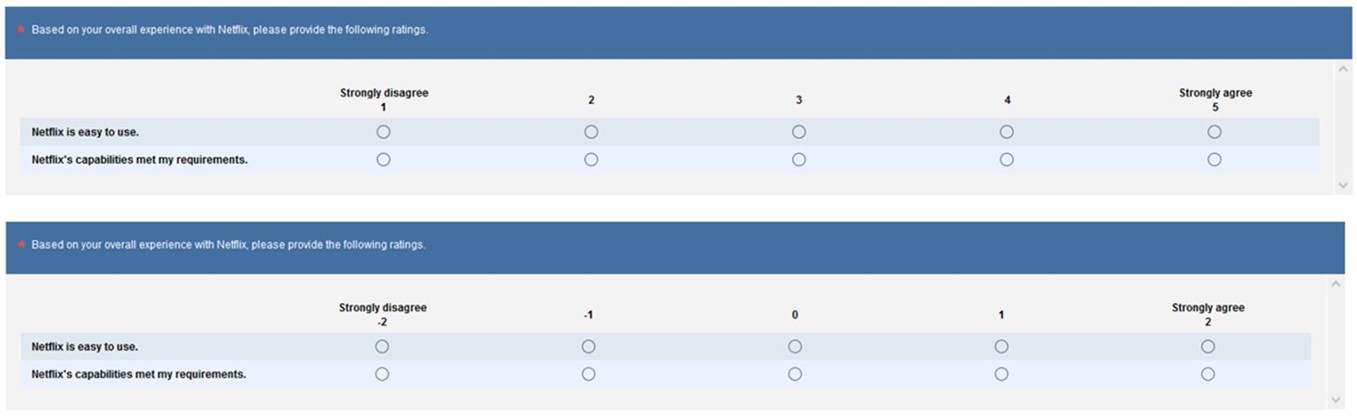
Figure 9: Standard (positive) numeric and negative-to-positive versions of the UMUX-Lite.
We found that the scale with the negative numbers had a similar response distribution to the standard numeric scales with a small, nonsignificant difference in means (0.7%). Takeaway: Negative numbers don’t seem to have much impact on UMUX-Lite scores. Researchers can use either standard or negative numbers for ratings of systems or experiences but should be cautious using them when asking participants to rate themselves.Summary
Across these eight topics, we found relatively small differences, typically not statistically significant. In general, we found the results interesting, but the effect sizes were trivial, no more than 1.5%. Figure 10 shows the size of the differences discussed here compared to the more substantial difference of using a three-point scale instead of an eleven-point scale in the LTR item used to compute the NPS. We summarized the study details and key findings in Table 1.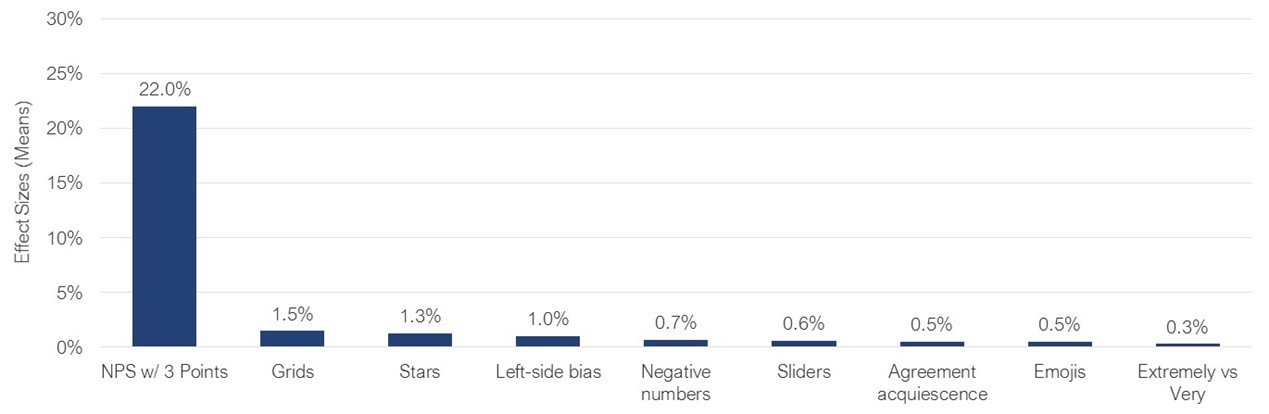
Figure 10: Nonsignificant effect sizes for eight investigations of item formats juxtaposed with an example of a significant effect (three-point NPS).
Our key recommendation is for researchers to watch out for strongly worded or overly broad generalizations:- “Agreement items are worthless.”
- “Pictures are easier to understand than numbers.”
- “People just pick the first option on the left.”
- “People don’t understand numbers.”
| Topic/Studies | n | Study Descriptions | Scales | Effect Size | Takeaway | Design: Between/Within |
|---|---|---|---|---|---|---|
| Left-Side Bias | 546 | IBM employees rating IBM Notes | 7-Point TAM | 1.0% | Slight left side tendency (not significant) but more errors (significant) | Between Subjects—Assigned to left to right vs right to left |
| Acquiescence Bias | 200 | IBM employees rating auto insurance websites | 7-Point UMUX-Lite | 0.5% | Slightly acquiescent tendency for agreement format (not significant) | Between Subjects—Assigned to agreement or item-specific format |
| Extremely vs Very | 213 | Recent retail purchase | 5-Point CSAT | 0.3% | Slightly higher mean satisfaction for “Very” (not significant) | Within Subjects—Item presentation counterbalanced and separated by other Qs |
| Grids | 399 | Ratings of ten products/services | 11-Point LTR | 1.5% | Slightly lower mean LTR in grids (not significant) | Between Subjects—Assigned to grid or separate |
| Emojis | 240 | Ratings of streaming entertainment services | 5-Point UMUX-Lite | 0.5% | Slightly lower means for face emojis (not significant) | Within Subjects—Greco-Latin counterbalancing |
| Sliders | 180 | Ratings of streaming entertainment services | 5-Point/ 101-point UMUX-Lite | 0.6% | Slightly higher means for sliders (not significant) | Within Subjects—Greco-Latin counterbalancing |
| Stars | 155 | Ratings of streaming entertainment services | 5-Point UMUX-Lite | 1.3% | Slightly higher means for stars (not significant) | Within Subjects—Greco-Latin counterbalancing |
| Negative Numbers | 256 | Ratings of streaming entertainment services | 5-Point UMUX-Lite | 0.7% | Slightly higher means for scales with negative numbers (not significant) | Within Subjects—Greco-Latin counterbalancing |